1.部署Prometheus
1.1.修改配置文件
- 准备工作
1
2
3
4
5
6
7
8
9
# 创建目录
mkdir -p /prometheus/prometheus
mkdir -p /prometheus/prometheus/data
mkdir -p /prometheus/prometheus/rules
chmod 777 -R /prometheus/prometheus/dat
# 创建配置文件
/prometheus/prometheus/prometheus.yml
touch prometheus.yml
- 修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
# 修改配置文件
/prometheus/prometheus/prometheus.yml
# prometheus.yml:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.17.88.22:9093
rule_files:
- "rules/*.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: alertmanager
scrape_interval: 5s
static_configs:
- targets: ['172.17.88.22:9093']
labels:
instance: alert
- job_name: centos-1
static_configs:
- targets: ['172.17.88.22:9100']
labels:
instance: node-1
- job_name: centos-2
static_configs:
- targets: ['172.17.88.19:9100']
labels:
instance: node-2
- job_name: centos-3
static_configs:
- targets: ['172.17.88.18:9100']
labels:
instance: node-3
- job_name: docker-1
static_configs:
- targets: ['172.17.88.22:9601']
labels:
instance: node-1
- job_name: docker-2
static_configs:
- targets: ['172.17.88.19:9601']
labels:
instance: node-2
- job_name: docker-3
static_configs:
- targets: ['172.17.88.18:9601']
labels:
instance: node-3
- job_name: redis-1
static_configs:
- targets: ['172.17.88.22:9121']
labels:
instance: redis-01
- job_name: redis-2
static_configs:
- targets: ['172.17.88.19:9121']
labels:
instance: redis-02
- job_name: redis-3
static_configs:
- targets: ['172.17.88.18:9121']
labels:
instance: redis-03
- job_name: rabbitmq-elk
static_configs:
- targets: ['172.17.88.22:9419']
labels:
instance: mq-elk
- job_name: rabbitmq-node
static_configs:
- targets: ['172.17.88.19:9419']
labels:
instance: mq-node
- job_name: postgres-1
static_configs:
- targets: ['172.17.88.22:9187']
labels:
instance: pg-1
- job_name: postgres-2
static_configs:
- targets: ['172.17.88.19:9187']
labels:
instance: pg-2
- job_name: es-cluster
static_configs:
- targets: ['172.17.88.22:9114', '172.17.88.19:9114', '172.17.88.18:9114']
labels:
instance: es
- job_name: mysql
static_configs:
- targets: ['172.17.88.22:9104']
labels:
instance: mysqld
- job_name: nginx-1
static_configs:
- targets: ['172.17.88.22:9913']
labels:
instance: nx-1
- job_name: nginx-3
static_configs:
- targets: ['172.17.88.18:9913']
labels:
instance: nx-3
- job_name: spring-boot-actuator
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['172.17.88.22:8888']
labels:
instance: spring-actuator
- job_name: haproxy
scrape_interval: 5s
static_configs:
- targets: ['172.17.88.18:9101']
labels:
instance: ha1
- job_name: HikariCP
scrape_interval: 5s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['172.17.88.22:28081']
labels:
instance: dbPool
1.2.配置告警规则
- 准备工作
1
2
3
4
5
6
7
8
9
# 创建目录
mkdir -p /prometheus/prometheus/rules
# 创建配置文件
/prometheus/prometheus/rules/memory_over.yml
/prometheus/prometheus/rules/node_down.yml
touch memory_over.yml
touch node_down.yml
- 修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 修改memory_over.yml
/prometheus/prometheus/rules/memory_over.yml
groups:
- name: example
rules:
- alert: NodeMemoryUsage
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: ": High Memory usage detected"
description: ": Memory usage is above 80% (current value is:)"
# 修改node_down.yml
/prometheus/prometheus/rules/node_down.yml
groups:
- name: node-up
rules:
- alert: node-up
expr: up{job="centos-3"} == 0
for: 15s
labels:
severity: 1
team: node
annotations:
summary: " 已停止运行!"
description: " 检测到异常停止!请重点关注!!!"
1.3.运行Docker
1
2
3
4
5
6
7
# 运行docker
docker run -d --network host --name prometheus --restart=always \
-v /prometheus/prometheus:/etc/prometheus \
-v /prometheus/prometheus/data:/prometheus \
-e TZ=Asia/Shanghai \
prom/prometheus
1
2
3
# 访问地址
http://47.95.238.119:9090
2.部署Alertmanager
2.1.修改配置文件
- 准备工作
1
2
3
4
5
6
7
8
# 创建目录
mkdir -p /prometheus/alertmanager/template
mkdir -p /prometheus/alertmanager/data
chmod 777 -R /prometheus/alertmanager/data
# 创建配置文件
/prometheus/alertmanager/alertmanager.yml
touch alertmanager.yml
- 修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
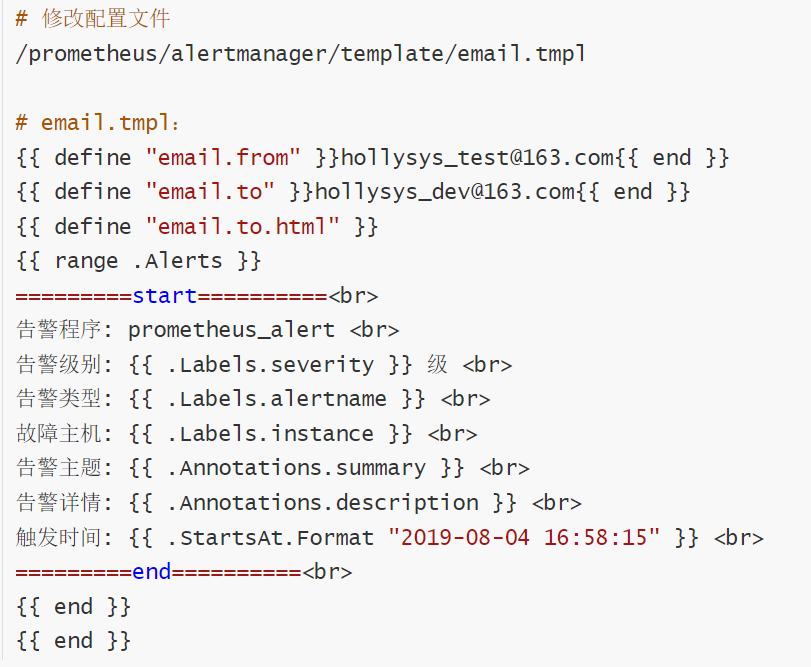
# 修改配置文件
/prometheus/prometheus/alertmanager.yml
# alertmanager.yml:
# 一条报警记录同时发给应用、邮箱、钉钉
global: # 全局配置项
resolve_timeout: 5m #超时,默认5min
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'hollysys_test@163.com'
smtp_auth_username: 'hollysys_test@163.com'
smtp_auth_password: 'NBJAGQUIDIJNAQDF' # 授权码:NBJAGQUIDIJNAQDF
smtp_require_tls: false
templates: # 定义模板信息
- 'template/*.tmpl' # 路径
route: # 路由
group_by: ['alertname'] # 报警分组依据
group_wait: 10s #组等待时间
group_interval: 10s # 发送前等待时间
repeat_interval: 1h #重复周期
receiver: default # 默认警报接收者
receivers: # 警报接收者
- name: default #警报名称
email_configs:
- to: '' #接收警报的email
html: '' # 模板
headers: { Subject: "[WARN] 报警邮件test" }
send_resolved: true
webhook_configs:
- url: http://172.17.88.22:8888/monitor
- url: http://172.17.88.22:8060/dingtalk/webhook1/send
send_resolved: true
inhibit_rules: # 告警抑制
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
2.2.Prometheus监控配置
1
2
3
4
5
6
7
8
# prometheus配置
- job_name: alertmanager
scrape_interval: 5s
static_configs:
- targets: ['172.17.88.18:9093']
labels:
instance: alert
1
2
3
4
# 访问地址
http://47.95.238.119:9093/metrics
curl '172.17.88.22:9093/metrics'
2.3.运行Docker
1
2
3
4
5
6
7
# 运行docker
docker run -d --network host --name alertmanager --restart=always \
-v /prometheus/alertmanager:/etc/alertmanager \
-v /prometheus/alertmanager/data:/alertmanager \
prom/alertmanager
1
2
3
### 访问地址
http://123.56.18.37:9093
3.部署Grafana
3.1.运行Docker
1
2
3
4
5
6
7
8
# 创建目录
mkdir -p /prometheus/grafana/data
chmod 777 -R /prometheus/grafana/data
# 运行docker
docker run -d --network host --name=grafana --restart=always \
-v /prometheus/grafana/data:/var/lib/grafana \
grafana/grafana
1
2
3
4
5
6
# 访问地址
http://47.95.238.119:3000
# 默认账号密码
用户名:admin
密码: admin
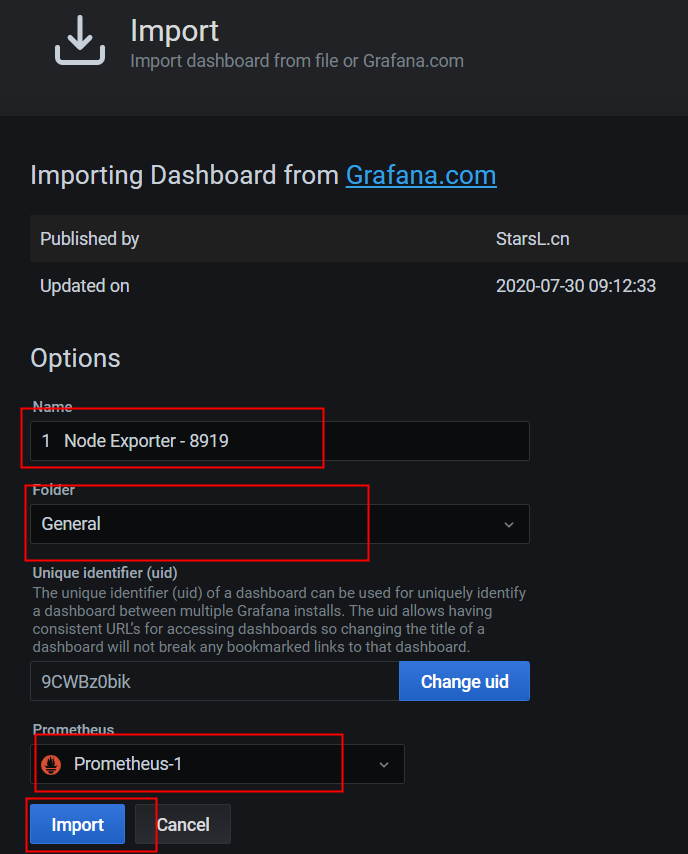
3.2. 配置数据源
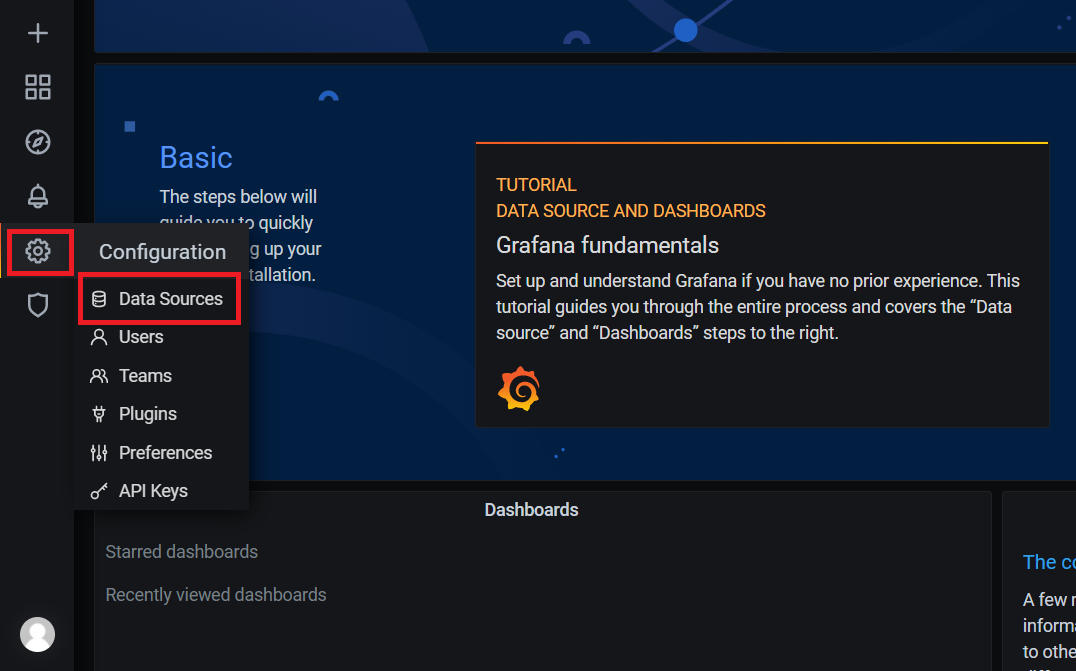
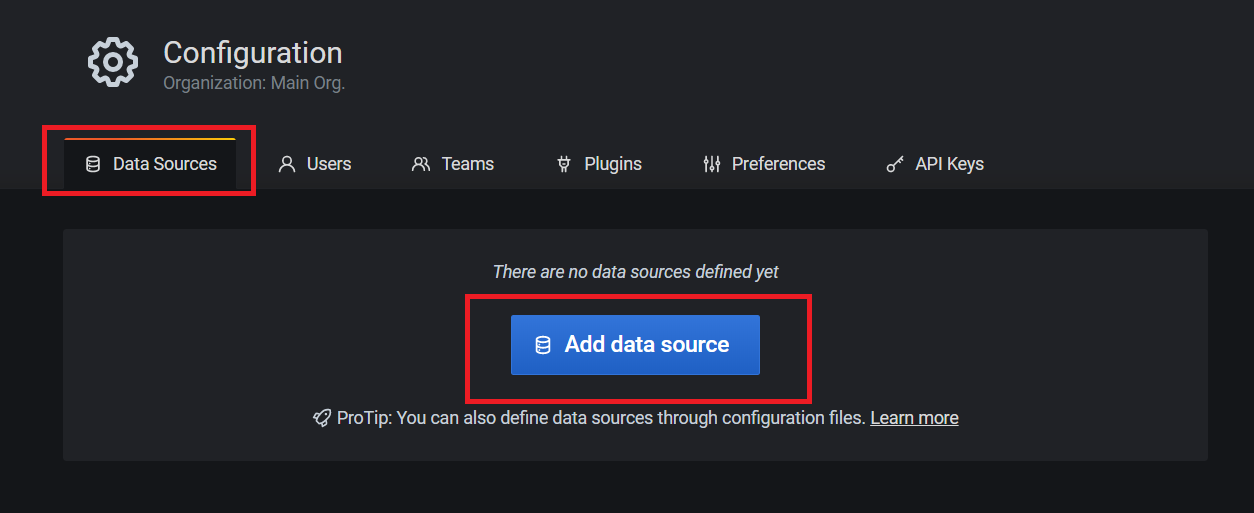
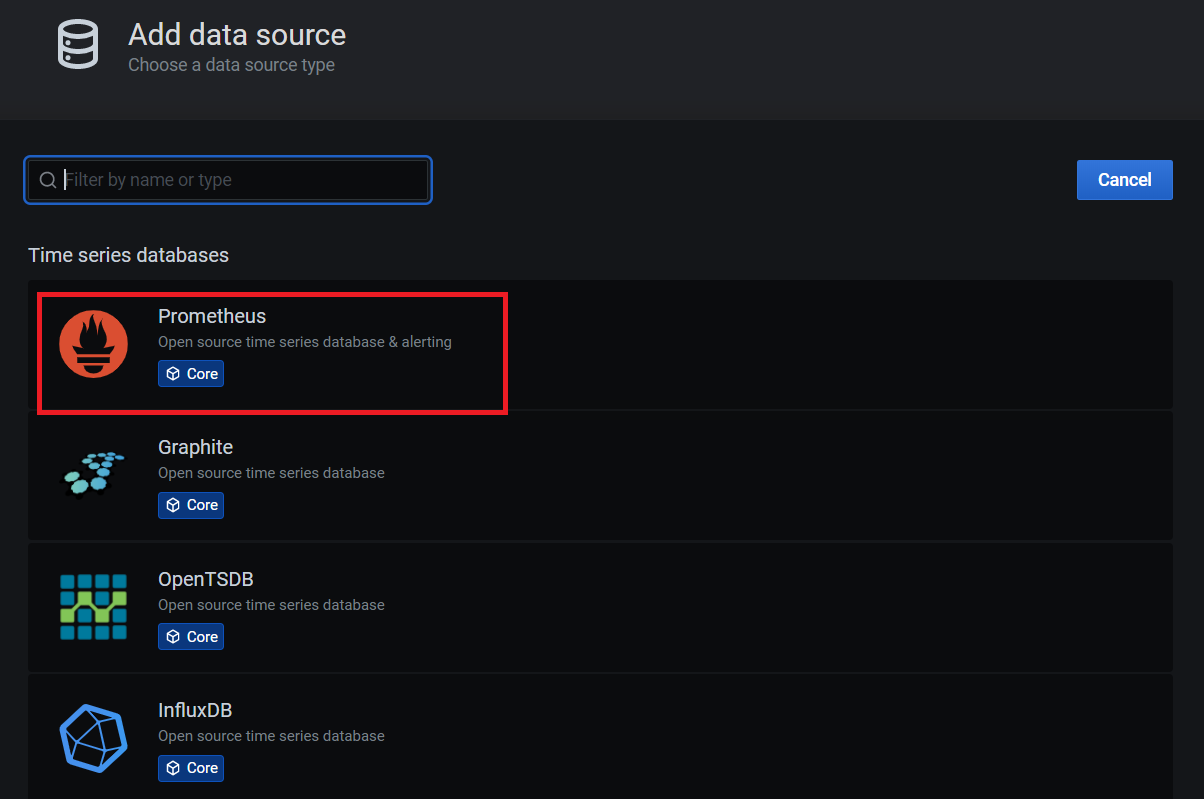
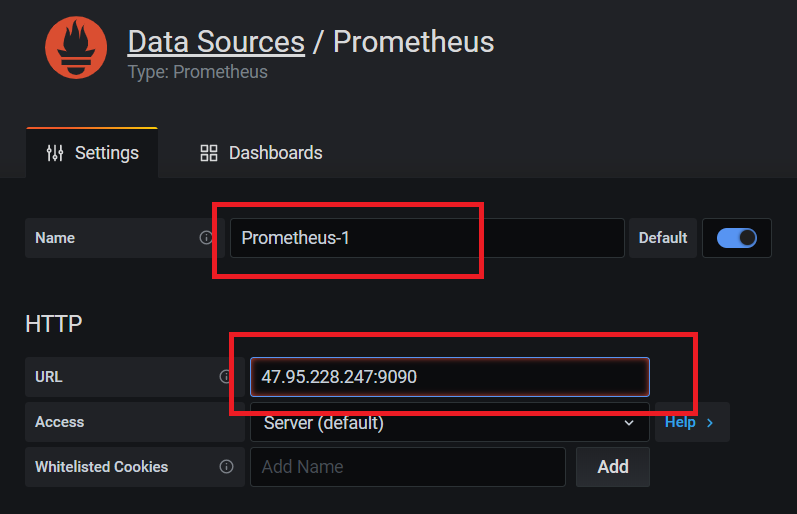
3.3. 配置dashboard
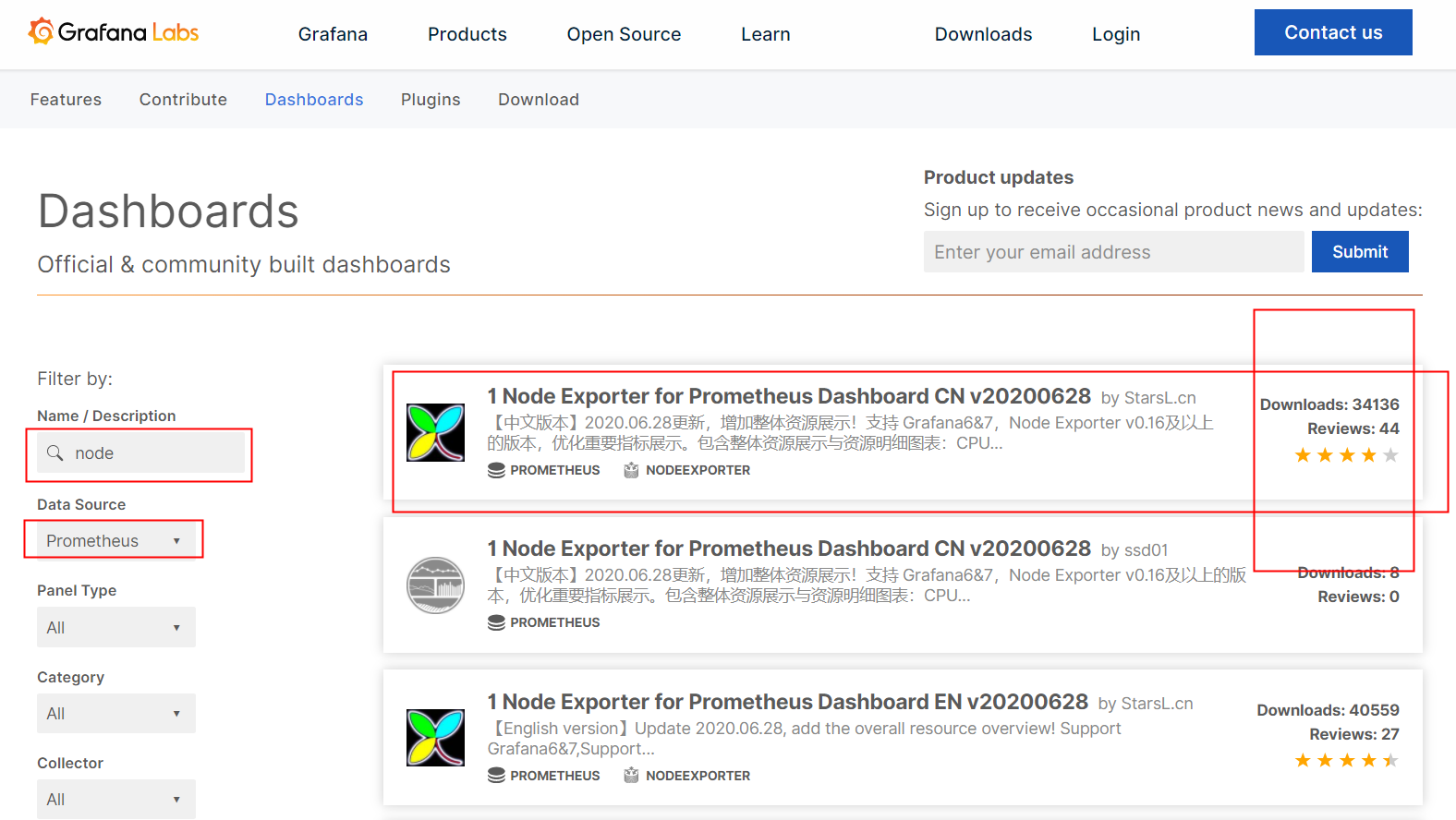
- 官网模板
1
2
3
4
# 访问官网地址
https://grafana.com/
https://grafana.com/grafana/dashboards
1
2
3
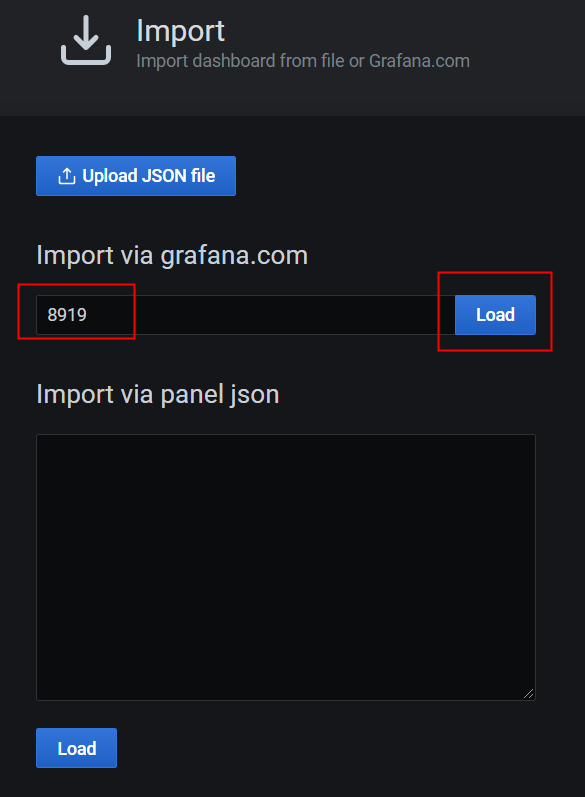
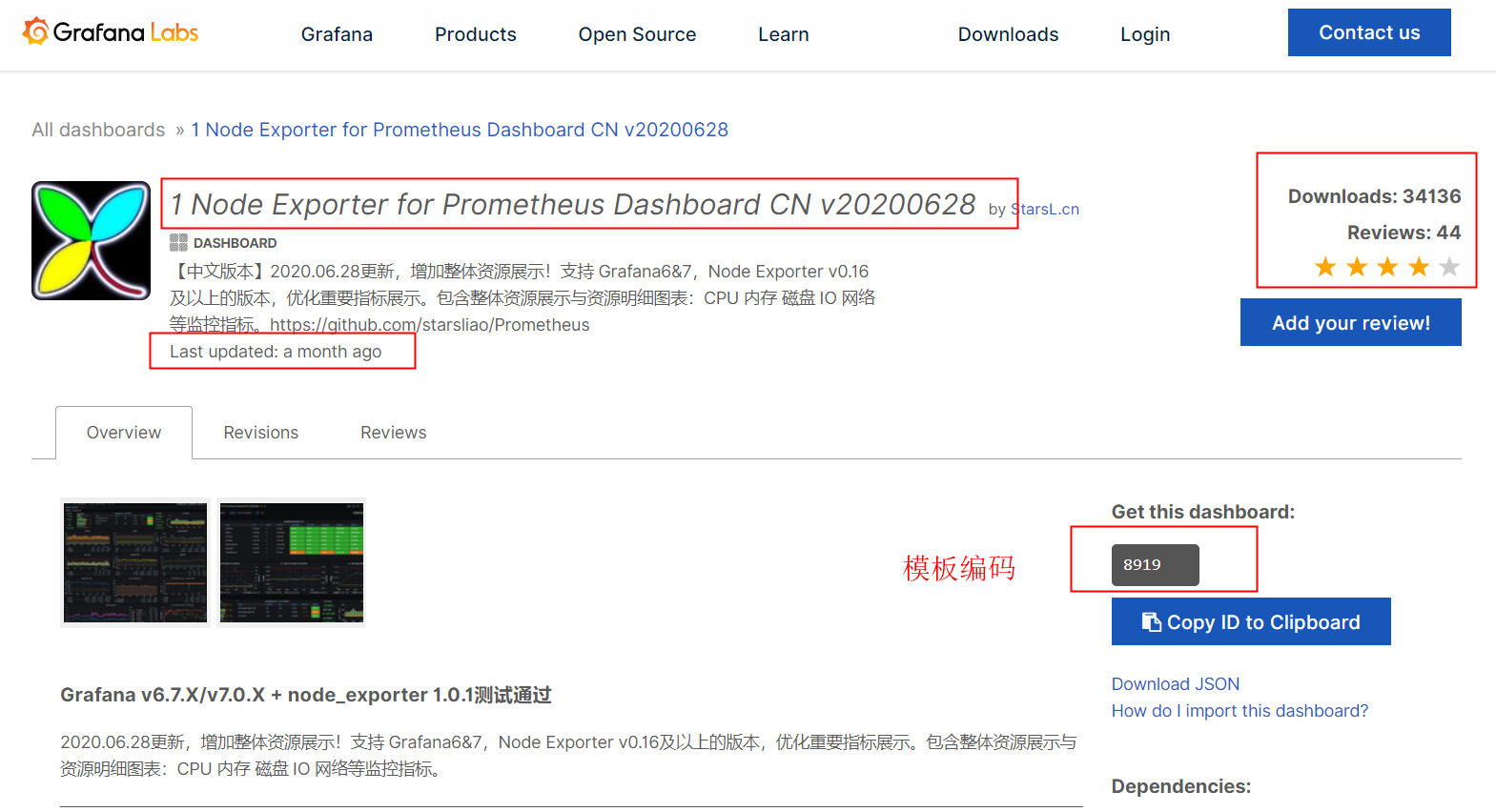
# 根据模板ID查找模板
ID: 8919
https://grafana.com/grafana/dashboards/8919
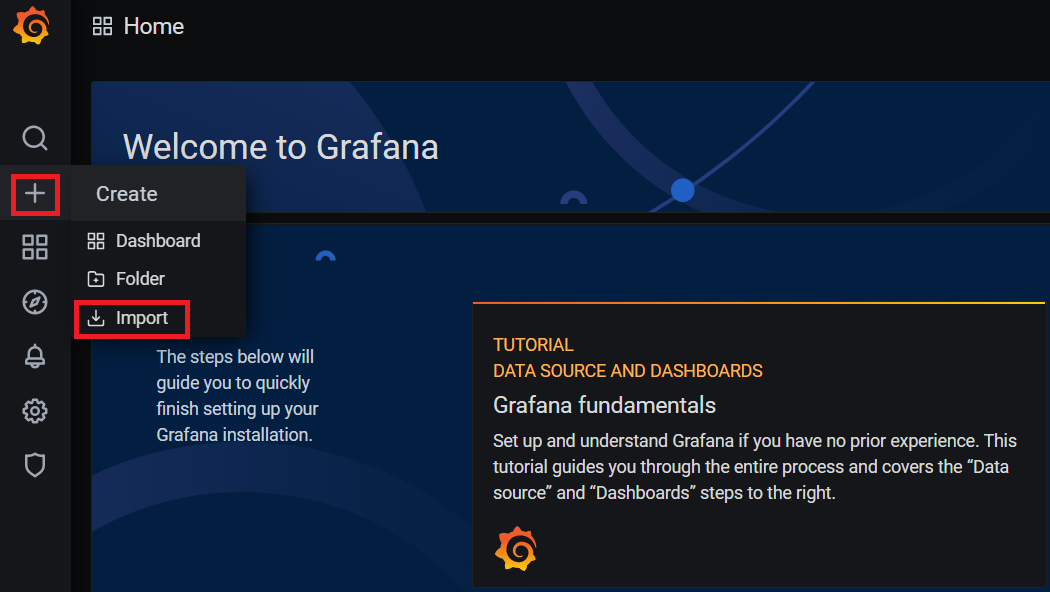
- 导入官网模板
1
2
3
# 访问Grafana地址
http://123.56.18.37:3000/login