系统监控 - Prometheus
1.k8s部署Prometheus
1.1.kube-prometheus
kube-prometheus 是一整套监控解决方案,它使用 Prometheus 采集集群指标,Grafana 做展示,包含如下组件:
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs (k8s-prometheus-adapter)
- kube-state-metrics
- Grafana
1
2
3
4
5
6
7
# 地址
https://github.com/prometheus-operator
https://github.com/prometheus-operator/kube-prometheus
https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.8.0.tar.gz
https://github.com/kubernetes-monitoring/kubernetes-mixin
kube-prometheus是coreos专门为kubernetes封装的一套高可用的监控预警,方便用户直接安装使用。
kube-prometheus是用于kubernetes集群监控的,所以它预先配置了从所有Kubernetes组件中收集指标。除此之外,它还提供了一组默认的仪表板和警报规则。许多有用的仪表板和警报都来自于kubernetes-mixin项目,与此项目类似,它也提供了jsonnet,供用户根据自己的需求定制。
1.兼容性
The following versions are supported and work as we test against these versions in their respective branches. But note that other versions might work!
| kube-prometheus stack | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 | Kubernetes 1.21 | Kubernetes 1.22 |
|---|---|---|---|---|---|
release-0.6 |
✗ | ✔ | ✗ | ✗ | ✗ |
release-0.7 |
✗ | ✔ | ✔ | ✗ | ✗ |
release-0.8 |
✗ | ✗ | ✔ | ✔ | ✗ |
release-0.9 |
✗ | ✗ | ✗ | ✔ | ✔ |
main |
✗ | ✗ | ✗ | ✔ | ✔ |
2.快速启动
使用manifests目录下的配置创建监控:
1
2
3
4
5
# Create the namespace and CRDs, and then wait for them to be availble before creating the remaining resources
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
1.2.kube-prometheus配置
1.2.1.manifests配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
[root@k8s-master1 manifests]# pwd
/k8s/operation/prometheus/kube-prometheus/manifests
[root@k8s-master1 manifests]# ll
total 1756
-rw-r--r-- 1 root root 875 Nov 24 11:43 alertmanager-alertmanager.yaml
-rw-r--r-- 1 root root 515 Nov 24 11:43 alertmanager-podDisruptionBudget.yaml
-rw-r--r-- 1 root root 6831 Nov 24 11:43 alertmanager-prometheusRule.yaml
-rw-r--r-- 1 root root 1169 Nov 24 11:43 alertmanager-secret.yaml
-rw-r--r-- 1 root root 301 Nov 24 11:43 alertmanager-serviceAccount.yaml
-rw-r--r-- 1 root root 540 Nov 24 11:43 alertmanager-serviceMonitor.yaml
-rw-r--r-- 1 root root 577 Nov 24 11:43 alertmanager-service.yaml
-rw-r--r-- 1 root root 278 Nov 24 11:43 blackbox-exporter-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 287 Nov 24 11:43 blackbox-exporter-clusterRole.yaml
-rw-r--r-- 1 root root 1392 Nov 24 11:43 blackbox-exporter-configuration.yaml
-rw-r--r-- 1 root root 3080 Nov 24 11:43 blackbox-exporter-deployment.yaml
-rw-r--r-- 1 root root 96 Nov 24 11:43 blackbox-exporter-serviceAccount.yaml
-rw-r--r-- 1 root root 680 Nov 24 11:43 blackbox-exporter-serviceMonitor.yaml
-rw-r--r-- 1 root root 540 Nov 24 11:43 blackbox-exporter-service.yaml
-rw-r--r-- 1 root root 721 Nov 24 11:43 grafana-dashboardDatasources.yaml
-rw-r--r-- 1 root root 1406527 Nov 24 11:43 grafana-dashboardDefinitions.yaml
-rw-r--r-- 1 root root 625 Nov 24 11:43 grafana-dashboardSources.yaml
-rw-r--r-- 1 root root 8159 Nov 25 13:12 grafana-deployment.yaml
-rw-r--r-- 1 root root 86 Nov 24 11:43 grafana-serviceAccount.yaml
-rw-r--r-- 1 root root 398 Nov 24 11:43 grafana-serviceMonitor.yaml
-rw-r--r-- 1 root root 452 Nov 24 11:43 grafana-service.yaml
-rw-r--r-- 1 root root 3319 Nov 24 11:43 kube-prometheus-prometheusRule.yaml
-rw-r--r-- 1 root root 63571 Nov 24 11:43 kubernetes-prometheusRule.yaml
-rw-r--r-- 1 root root 6836 Nov 24 11:43 kubernetes-serviceMonitorApiserver.yaml
-rw-r--r-- 1 root root 440 Nov 24 11:43 kubernetes-serviceMonitorCoreDNS.yaml
-rw-r--r-- 1 root root 6355 Nov 24 11:43 kubernetes-serviceMonitorKubeControllerManager.yaml
-rw-r--r-- 1 root root 7171 Nov 24 11:43 kubernetes-serviceMonitorKubelet.yaml
-rw-r--r-- 1 root root 530 Nov 24 11:43 kubernetes-serviceMonitorKubeScheduler.yaml
-rw-r--r-- 1 root root 464 Nov 24 11:43 kube-state-metrics-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 1712 Nov 24 11:43 kube-state-metrics-clusterRole.yaml
-rw-r--r-- 1 root root 2957 Nov 24 11:43 kube-state-metrics-deployment.yaml
-rw-r--r-- 1 root root 1864 Nov 24 11:43 kube-state-metrics-prometheusRule.yaml
-rw-r--r-- 1 root root 280 Nov 24 11:43 kube-state-metrics-serviceAccount.yaml
-rw-r--r-- 1 root root 1011 Nov 24 11:43 kube-state-metrics-serviceMonitor.yaml
-rw-r--r-- 1 root root 580 Nov 24 11:43 kube-state-metrics-service.yaml
-rw-r--r-- 1 root root 444 Nov 24 11:43 node-exporter-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 461 Nov 24 11:43 node-exporter-clusterRole.yaml
-rw-r--r-- 1 root root 3020 Nov 24 11:43 node-exporter-daemonset.yaml
-rw-r--r-- 1 root root 12975 Nov 24 11:43 node-exporter-prometheusRule.yaml
-rw-r--r-- 1 root root 270 Nov 24 11:43 node-exporter-serviceAccount.yaml
-rw-r--r-- 1 root root 850 Nov 24 11:43 node-exporter-serviceMonitor.yaml
-rw-r--r-- 1 root root 492 Nov 24 11:43 node-exporter-service.yaml
-rw-r--r-- 1 root root 482 Nov 24 11:43 prometheus-adapter-apiService.yaml
-rw-r--r-- 1 root root 576 Nov 24 11:43 prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml
-rw-r--r-- 1 root root 494 Nov 24 11:43 prometheus-adapter-clusterRoleBindingDelegator.yaml
-rw-r--r-- 1 root root 471 Nov 24 11:43 prometheus-adapter-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 378 Nov 24 11:43 prometheus-adapter-clusterRoleServerResources.yaml
-rw-r--r-- 1 root root 409 Nov 24 11:43 prometheus-adapter-clusterRole.yaml
-rw-r--r-- 1 root root 1836 Nov 24 11:43 prometheus-adapter-configMap.yaml
-rw-r--r-- 1 root root 1804 Nov 24 11:43 prometheus-adapter-deployment.yaml
-rw-r--r-- 1 root root 515 Nov 24 11:43 prometheus-adapter-roleBindingAuthReader.yaml
-rw-r--r-- 1 root root 287 Nov 24 11:43 prometheus-adapter-serviceAccount.yaml
-rw-r--r-- 1 root root 677 Nov 24 11:43 prometheus-adapter-serviceMonitor.yaml
-rw-r--r-- 1 root root 501 Nov 24 11:43 prometheus-adapter-service.yaml
-rw-r--r-- 1 root root 447 Nov 24 11:43 prometheus-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 394 Nov 24 11:43 prometheus-clusterRole.yaml
-rw-r--r-- 1 root root 4930 Nov 24 11:43 prometheus-operator-prometheusRule.yaml
-rw-r--r-- 1 root root 715 Nov 24 11:43 prometheus-operator-serviceMonitor.yaml
-rw-r--r-- 1 root root 499 Nov 24 11:43 prometheus-podDisruptionBudget.yaml
-rw-r--r-- 1 root root 12732 Nov 24 11:43 prometheus-prometheusRule.yaml
-rw-r--r-- 1 root root 1418 Nov 25 14:12 prometheus-prometheus.yaml
-rw-r--r-- 1 root root 471 Nov 24 11:43 prometheus-roleBindingConfig.yaml
-rw-r--r-- 1 root root 1547 Nov 24 11:43 prometheus-roleBindingSpecificNamespaces.yaml
-rw-r--r-- 1 root root 366 Nov 24 11:43 prometheus-roleConfig.yaml
-rw-r--r-- 1 root root 2047 Nov 24 11:43 prometheus-roleSpecificNamespaces.yaml
-rw-r--r-- 1 root root 271 Nov 24 11:43 prometheus-serviceAccount.yaml
-rw-r--r-- 1 root root 531 Nov 24 11:43 prometheus-serviceMonitor.yaml
-rw-r--r-- 1 root root 558 Nov 24 11:43 prometheus-service.yaml
drwxr-xr-x 2 root root 4096 Nov 25 14:24 setup
[root@k8s-master1 manifests]#
[root@k8s-master1 manifests]# cd setup/
[root@k8s-master1 setup]# ll
total 1028
-rw-r--r-- 1 root root 60 Nov 24 11:43 0namespace-namespace.yaml
-rw-r--r-- 1 root root 122054 Nov 24 11:43 prometheus-operator-0alertmanagerConfigCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 247084 Nov 24 11:43 prometheus-operator-0alertmanagerCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 20907 Nov 24 11:43 prometheus-operator-0podmonitorCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 20077 Nov 24 11:43 prometheus-operator-0probeCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 327667 Nov 24 11:43 prometheus-operator-0prometheusCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 3618 Nov 24 11:43 prometheus-operator-0prometheusruleCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 21941 Nov 24 11:43 prometheus-operator-0servicemonitorCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 253551 Nov 24 11:43 prometheus-operator-0thanosrulerCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 471 Nov 24 11:43 prometheus-operator-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 1377 Nov 24 11:43 prometheus-operator-clusterRole.yaml
-rw-r--r-- 1 root root 2328 Nov 25 14:24 prometheus-operator-deployment.yaml
-rw-r--r-- 1 root root 285 Nov 24 11:43 prometheus-operator-serviceAccount.yaml
-rw-r--r-- 1 root root 515 Nov 24 11:43 prometheus-operator-service.yaml
1.service说明
1
2
3
4
5
6
7
8
9
10
# prometheus的service
[root@k8s-master manifests]# vim prometheus-service.yaml
# alertmanager的service
[root@k8s-master manifests]# vim alertmanager-service.yaml
# grafana的service
[root@k8s-master manifests]# vim grafana-service.yaml
2.修改副本数
默认alertmanager副本数为3,prometheus副本数为2,grafana副本数为1。这是官方基于高可用考虑的
1
2
3
4
5
6
7
8
# alertmanager
vi alertmanager-alertmanager.yaml
# prometheus
vi prometheus-prometheus.yaml
# grafana
vi grafana-deployment.yaml
1.2.2.修改镜像源
国外镜像源某些镜像无法拉取,我们这里修改prometheus-operator,prometheus,alertmanager,kube-state-metrics,node-exporter,prometheus-adapter的镜像源为国内镜像源。我这里使用的是中科大的镜像源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' setup/prometheus-operator-deployment.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' prometheus-prometheus.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' alertmanager-alertmanager.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' kube-state-metrics-deployment.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' node-exporter-daemonset.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' prometheus-adapter-deployment.yaml
[root@k8s-master1 manifests]# sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' setup/prometheus-operator-deployment.yaml
[root@k8s-master1 manifests]# sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' prometheus-prometheus.yaml
[root@k8s-master1 manifests]# sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' alertmanager-alertmanager.yaml
[root@k8s-master1 manifests]# sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' kube-state-metrics-deployment.yaml
[root@k8s-master1 manifests]# sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' node-exporter-daemonset.yaml
[root@k8s-master1 manifests]# sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' prometheus-adapter-deployment.yaml
1.2.3.Prometheus数据持久化
1.修改文件 manifests/prometheus-prometheus.yaml
1
2
3
4
5
6
7
8
9
10
#-----storage-----
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
#-----------------
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 完整配置
# prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
externalLabels: {}
#-----storage-----
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
#-----------------
image: quay.io/prometheus/prometheus:v2.26.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.26.0
在修改yaml文件之后执行kubectl apply -f manifests/prometheus-prometheus.yaml命令,会自动创建两个指定大小的pv卷,因为会为prometheus的备份(prometheus-k8s-0,prometheus-k8s-1)也创建一个pv(我是用的是ceph-rbd,也可以换成其他的文件系统),但是pv卷创建之后,无法修改,所以最好先考虑好合适的参数配置,比如访问模式和容量大小。在下次重新apply prometheus-prometheus.yaml时,数据会存到已经创建的pv卷中。
1.2.4修改存储数据时间
prometheus operator数据保留天数,根据官方文档的说明,默认prometheus operator数据存储的时间为1d,这个时候无论你prometheus operator如何进行持久化,都没有作用,因为数据只保留了1天,那么你是无法看到更多天数的数据
官方文档可以配置的说明
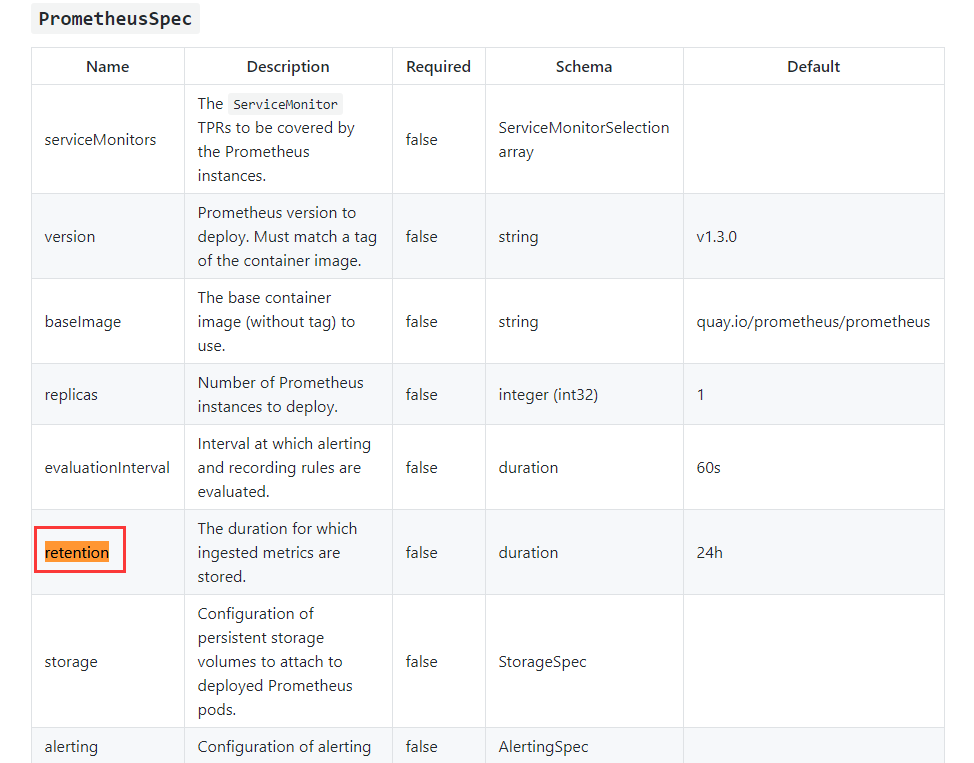
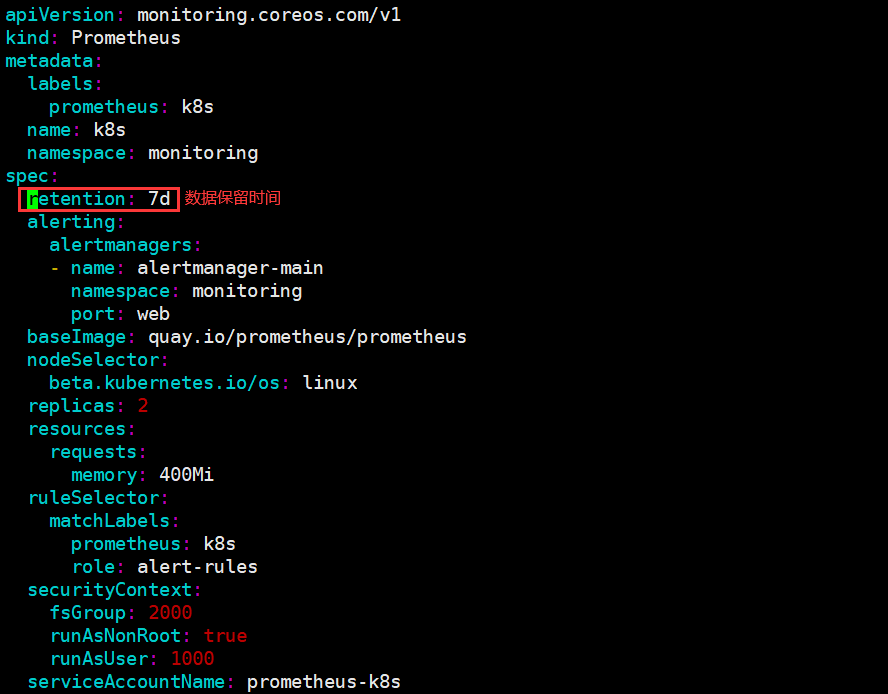
实际上修改prometheus operator时间是通过retention参数进行修改,上面也提示了在prometheus.spec下填写
修改方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
[root@k8s-master manifests]# pwd
/k8s/monitoring/prometheus/kube-prometheus-0.8.0/manifests
[root@k8s-master manifests]# vim prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
......
spec:
retention: 7d # 数据保留时间
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
externalLabels: {}
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 40Gi
image: quay.mirrors.ustc.edu.cn/prometheus/prometheus:v2.26.0
# 如果已经安装了可以直接修改prometheus-prometheus.yaml 然后通过kubectl apply -f 刷新即可
# 修改完毕后检查pod运行状态是否正常
# 接下来可以访问grafana或者prometheus ui进行检查 (我这里修改完毕后等待2天,检查数据是否正常)
1.2.5.Grafana配置持久化
1.创建grafana-pvc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
storageClassName: rook-cephfs
然后在grafana-deployment.yaml将emptydir存储方式改为pvc方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#- emptyDir: {}
# name: grafana-storage
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
- name: grafana-datasources
secret:
secretName: grafana-datasources
- configMap:
name: grafana-dashboards
name: grafana-dashboards
- configMap:
name: grafana-dashboard-apiserver
name: grafana-dashboard-apiserver
- configMap:
name: grafana-dashboard-controller-manager
........
文件存储(CephFS):适用Deployment,多个Pod文件共享;
1.3.安装kube-prometheus
1
2
3
4
5
6
7
# Create the namespace and CRDs, and then wait for them to be available before creating the remaining resources
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
1.安装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
[root@k8s-master1 manifests]# cd kube-prometheus
# 1.创建prometheus-operator
[root@k8s-master1 kube-prometheus]# kubectl create -f manifests/setup
namespace/monitoring created
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
service/prometheus-operator created
serviceaccount/prometheus-operator created
# 查看
[root@k8s-master1 ~]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/prometheus-operator-6587df967f-xqv5z 2/2 Running 0 57s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus-operator ClusterIP None <none> 8443/TCP 57s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-operator 1/1 1 1 57s
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-operator-6587df967f 1 1 1 57s
# 检查
[root@k8s-master1 kube-prometheus]# until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
No resources found
# 2.创建prometheus
[root@k8s-master kube-prometheus]# kubectl create -f manifests/
alertmanager.monitoring.coreos.com/main created
poddisruptionbudget.policy/alertmanager-main created
prometheusrule.monitoring.coreos.com/alertmanager-main-rules created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager created
clusterrole.rbac.authorization.k8s.io/blackbox-exporter created
clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created
configmap/blackbox-exporter-configuration created
deployment.apps/blackbox-exporter created
service/blackbox-exporter created
serviceaccount/blackbox-exporter created
servicemonitor.monitoring.coreos.com/blackbox-exporter created
secret/grafana-datasources created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-statefulset created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
prometheusrule.monitoring.coreos.com/kube-prometheus-rules created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
prometheusrule.monitoring.coreos.com/node-exporter-rules created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
prometheusrule.monitoring.coreos.com/prometheus-operator-rules created
servicemonitor.monitoring.coreos.com/prometheus-operator created
poddisruptionbudget.policy/prometheus-k8s created
prometheus.monitoring.coreos.com/k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-k8s created
Error from server (AlreadyExists): error when creating "manifests/prometheus-adapter-apiService.yaml": apiservices.apiregistration.k8s.io "v1beta1.metrics.k8s.io" already exists
Error from server (AlreadyExists): error when creating "manifests/prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml": clusterroles.rbac.authorization.k8s.io "system:aggregated-metrics-reader" already exists
# 查看
[root@k8s-master prometheus]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 119m
pod/alertmanager-main-1 2/2 Running 0 119m
pod/alertmanager-main-2 2/2 Running 0 119m
pod/blackbox-exporter-55c457d5fb-78bs9 3/3 Running 0 119m
pod/grafana-9df57cdc4-gnbkp 1/1 Running 0 119m
pod/kube-state-metrics-76f6cb7996-cfq79 2/3 ImagePullBackOff 0 62m
pod/node-exporter-g5vqs 2/2 Running 0 119m
pod/node-exporter-ks6h7 2/2 Running 0 119m
pod/node-exporter-s8c4m 2/2 Running 0 119m
pod/node-exporter-tlmp6 2/2 Running 0 119m
pod/prometheus-adapter-59df95d9f5-jdpzp 1/1 Running 0 119m
pod/prometheus-adapter-59df95d9f5-k6t66 1/1 Running 0 119m
pod/prometheus-k8s-0 2/2 Running 1 119m
pod/prometheus-k8s-1 2/2 Running 1 119m
pod/prometheus-operator-7775c66ccf-qdg56 2/2 Running 0 127m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.96.148.16 <none> 9093/TCP 119m
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 119m
service/blackbox-exporter ClusterIP 10.102.106.12 <none> 9115/TCP,19115/TCP 119m
service/grafana ClusterIP 10.96.45.54 <none> 3000/TCP 119m
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 119m
service/node-exporter ClusterIP None <none> 9100/TCP 119m
service/prometheus-adapter ClusterIP 10.108.127.216 <none> 443/TCP 119m
service/prometheus-k8s ClusterIP 10.100.120.200 <none> 9090/TCP 119m
service/prometheus-operated ClusterIP None <none> 9090/TCP 119m
service/prometheus-operator ClusterIP None <none> 8443/TCP 127m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 4 4 4 4 4 kubernetes.io/os=linux 119m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/blackbox-exporter 1/1 1 1 119m
deployment.apps/grafana 1/1 1 1 119m
deployment.apps/kube-state-metrics 0/1 1 0 119m
deployment.apps/prometheus-adapter 2/2 2 2 119m
deployment.apps/prometheus-operator 1/1 1 1 127m
NAME DESIRED CURRENT READY AGE
replicaset.apps/blackbox-exporter-55c457d5fb 1 1 1 119m
replicaset.apps/grafana-9df57cdc4 1 1 1 119m
replicaset.apps/kube-state-metrics-76f6cb7996 1 1 0 119m
replicaset.apps/prometheus-adapter-59df95d9f5 2 2 2 119m
replicaset.apps/prometheus-operator-7775c66ccf 1 1 1 127m
NAME READY AGE
statefulset.apps/alertmanager-main 3/3 119m
statefulset.apps/prometheus-k8s 2/2 119m
[root@k8s-master prometheus]# until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
NAMESPACE NAME AGE
monitoring alertmanager 119m
monitoring blackbox-exporter 119m
monitoring coredns 119m
monitoring grafana 119m
monitoring kube-apiserver 119m
monitoring kube-controller-manager 119m
monitoring kube-scheduler 119m
monitoring kube-state-metrics 119m
monitoring kubelet 119m
monitoring node-exporter 119m
monitoring prometheus-adapter 119m
monitoring prometheus-k8s 119m
monitoring prometheus-operator 119m
[root@k8s-master prometheus]# kubectl get pod -n monitoring -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-main-0 2/2 Running 0 3h13m 10.244.36.95 k8s-node1 <none> <none>
alertmanager-main-1 2/2 Running 0 3h13m 10.244.36.121 k8s-node1 <none> <none>
alertmanager-main-2 2/2 Running 0 3h13m 10.244.36.92 k8s-node1 <none> <none>
blackbox-exporter-55c457d5fb-78bs9 3/3 Running 0 3h13m 10.244.36.104 k8s-node1 <none> <none>
grafana-9df57cdc4-gnbkp 1/1 Running 0 3h13m 10.244.36.123 k8s-node1 <none> <none>
kube-state-metrics-76f6cb7996-cfq79 3/3 Running 0 136m 10.244.107.193 k8s-node3 <none> <none>
node-exporter-g5vqs 2/2 Running 0 3h13m 172.51.216.84 k8s-node3 <none> <none>
node-exporter-ks6h7 2/2 Running 0 3h13m 172.51.216.81 k8s-master <none> <none>
node-exporter-s8c4m 2/2 Running 0 3h13m 172.51.216.82 k8s-node1 <none> <none>
node-exporter-tlmp6 2/2 Running 0 3h13m 172.51.216.83 k8s-node2 <none> <none>
prometheus-adapter-59df95d9f5-jdpzp 1/1 Running 0 3h13m 10.244.36.125 k8s-node1 <none> <none>
prometheus-adapter-59df95d9f5-k6t66 1/1 Running 0 3h13m 10.244.169.133 k8s-node2 <none> <none>
prometheus-k8s-0 2/2 Running 1 3h13m 10.244.169.143 k8s-node2 <none> <none>
prometheus-k8s-1 2/2 Running 1 3h13m 10.244.36.86 k8s-node1 <none> <none>
prometheus-operator-7775c66ccf-qdg56 2/2 Running 0 3h21m 10.244.36.89 k8s-node1 <none> <none>
2.镜像拉取处理
1
2
3
4
5
6
7
8
9
10
11
12
13
# 不能拉取的镜像
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0
# 处理方式
docker pull bitnami/kube-state-metrics:2.0.0
docker tag bitnami/kube-state-metrics:2.0.0 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0
# 参考地址
https://hub.docker.com/r/bitnami/kube-state-metrics
https://github.com/kubernetes/kube-state-metrics
https://github.com/kubernetes/kube-state-metrics
At most, 5 kube-state-metrics and 5 kubernetes releases will be recorded below.
| kube-state-metrics | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 | Kubernetes 1.21 | Kubernetes 1.22 |
|---|---|---|---|---|---|
| v1.9.8 | - | - | - | - | - |
| v2.0.0 | -/✓ | ✓ | ✓ | -/✓ | -/✓ |
| v2.1.1 | -/✓ | ✓ | ✓ | ✓ | -/✓ |
| v2.2.4 | -/✓ | ✓ | ✓ | ✓ | ✓ |
| master | -/✓ | ✓ | ✓ | ✓ | ✓ |
✓Fully supported version range.-The Kubernetes cluster has features the client-go library can’t use (additional API objects, deprecated APIs, etc).
3.创建Ingress
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# prometheus-ing.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ing
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: prometheus.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
- host: grafana.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
- host: alertmanager.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
[root@k8s-master1 prometheus]# kubectl apply -f prometheus-ing.yaml
ingress.networking.k8s.io/prometheus-ing created
[root@k8s-master prometheus]# kubectl get ing -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
prometheus-ing <none> prometheus.k8s.com,grafana.k8s.com,alertmanager.k8s.com 80 14s
在本机添加域名解析
C:\Windows\System32\drivers\etc
在hosts文件添加域名解析(master主机的iP地址)
172.51.216.81 prometheus.k8s.com
172.51.216.81 grafana.k8s.com
172.51.216.81 alertmanager.k8s.com
[root@k8s-master prometheus]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.106.196.185 <none> 80:31356/TCP,443:31221/TCP 171m
ingress-nginx-controller-admission ClusterIP 10.103.157.181 <none> 443/TCP 171m
# ingress地址
# 在本机浏览器输入:
http://prometheus.k8s.com:31356/
http://alertmanager.k8s.com:31356/
http://grafana.k8s.com:31356/
admin/admin
1.4.测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
[root@k8s-master1 prometheus]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 27m
pod/alertmanager-main-1 2/2 Running 0 27m
pod/alertmanager-main-2 2/2 Running 0 27m
pod/blackbox-exporter-55c457d5fb-zmnkv 3/3 Running 0 27m
pod/grafana-684679d675-7cr4l 1/1 Running 0 27m
pod/kube-state-metrics-5df9d95bc6-5pqb4 3/3 Running 0 27m
pod/node-exporter-bhhwf 2/2 Running 0 27m
pod/node-exporter-f5ntl 2/2 Running 0 27m
pod/node-exporter-jc6jg 2/2 Running 0 27m
pod/node-exporter-kjznp 2/2 Running 0 27m
pod/node-exporter-lkqpv 2/2 Running 0 27m
pod/node-exporter-vc7j8 2/2 Running 0 27m
pod/node-exporter-w9rdn 2/2 Running 0 27m
pod/prometheus-adapter-59df95d9f5-25xll 1/1 Running 0 27m
pod/prometheus-adapter-59df95d9f5-zfrnj 1/1 Running 0 27m
pod/prometheus-k8s-0 2/2 Running 3 27m
pod/prometheus-k8s-1 2/2 Running 1 27m
pod/prometheus-operator-6587df967f-xqv5z 2/2 Running 0 29m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.1.45.70 <none> 9093/TCP 27m
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 27m
service/blackbox-exporter ClusterIP 10.1.102.125 <none> 9115/TCP,19115/TCP 27m
service/grafana ClusterIP 10.1.149.236 <none> 3000/TCP 27m
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 27m
service/node-exporter ClusterIP None <none> 9100/TCP 27m
service/prometheus-adapter ClusterIP 10.1.51.197 <none> 443/TCP 27m
service/prometheus-k8s ClusterIP 10.1.226.110 <none> 9090/TCP 27m
service/prometheus-operated ClusterIP None <none> 9090/TCP 27m
service/prometheus-operator ClusterIP None <none> 8443/TCP 29m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 7 7 7 7 7 kubernetes.io/os=linux 27m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/blackbox-exporter 1/1 1 1 27m
deployment.apps/grafana 1/1 1 1 27m
deployment.apps/kube-state-metrics 1/1 1 1 27m
deployment.apps/prometheus-adapter 2/2 2 2 27m
deployment.apps/prometheus-operator 1/1 1 1 29m
NAME DESIRED CURRENT READY AGE
replicaset.apps/blackbox-exporter-55c457d5fb 1 1 1 27m
replicaset.apps/grafana-684679d675 1 1 1 27m
replicaset.apps/kube-state-metrics-5df9d95bc6 1 1 1 27m
replicaset.apps/prometheus-adapter-59df95d9f5 2 2 2 27m
replicaset.apps/prometheus-operator-6587df967f 1 1 1 29m
NAME READY AGE
statefulset.apps/alertmanager-main 3/3 27m
statefulset.apps/prometheus-k8s 2/2 27m
访问Grafana,导入模板 8919、11074
1.5.微服务监控
1.5.1.微服务监控指标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
# 查看eureka指标
http://eureka.pro.com:31356/actuator
{"_links":{"self":{"href":"http://eureka.pro.com/actuator","templated":false},"archaius":{"href":"http://eureka.pro.com/actuator/archaius","templated":false},"beans":{"href":"http://eureka.pro.com/actuator/beans","templated":false},"caches":{"href":"http://eureka.pro.com/actuator/caches","templated":false},"caches-cache":{"href":"http://eureka.pro.com/actuator/caches/{cache}","templated":true},"health-path":{"href":"http://eureka.pro.com/actuator/health/{*path}","templated":true},"health":{"href":"http://eureka.pro.com/actuator/health","templated":false},"info":{"href":"http://eureka.pro.com/actuator/info","templated":false},"conditions":{"href":"http://eureka.pro.com/actuator/conditions","templated":false},"configprops":{"href":"http://eureka.pro.com/actuator/configprops","templated":false},"env-toMatch":{"href":"http://eureka.pro.com/actuator/env/{toMatch}","templated":true},"env":{"href":"http://eureka.pro.com/actuator/env","templated":false},"loggers-name":{"href":"http://eureka.pro.com/actuator/loggers/{name}","templated":true},"loggers":{"href":"http://eureka.pro.com/actuator/loggers","templated":false},"heapdump":{"href":"http://eureka.pro.com/actuator/heapdump","templated":false},"threaddump":{"href":"http://eureka.pro.com/actuator/threaddump","templated":false},"prometheus":{"href":"http://eureka.pro.com/actuator/prometheus","templated":false},"metrics":{"href":"http://eureka.pro.com/actuator/metrics","templated":false},"metrics-requiredMetricName":{"href":"http://eureka.pro.com/actuator/metrics/{requiredMetricName}","templated":true},"scheduledtasks":{"href":"http://eureka.pro.com/actuator/scheduledtasks","templated":false},"mappings":{"href":"http://eureka.pro.com/actuator/mappings","templated":false},"refresh":{"href":"http://eureka.pro.com/actuator/refresh","templated":false},"features":{"href":"http://eureka.pro.com/actuator/features","templated":false},"service-registry":{"href":"http://eureka.pro.com/actuator/service-registry","templated":false}}}
http://eureka.pro.com:31356/actuator/prometheus
# HELP system_cpu_count The number of processors available to the Java virtual machine
# TYPE system_cpu_count gauge
system_cpu_count{application="msa-eureka",region="iids",} 1.0
# HELP jvm_buffer_count_buffers An estimate of the number of buffers in the pool
# TYPE jvm_buffer_count_buffers gauge
jvm_buffer_count_buffers{application="msa-eureka",id="mapped",region="iids",} 0.0
jvm_buffer_count_buffers{application="msa-eureka",id="direct",region="iids",} 10.0
# HELP jvm_threads_peak_threads The peak live thread count since the Java virtual machine started or peak was reset
# TYPE jvm_threads_peak_threads gauge
jvm_threads_peak_threads{application="msa-eureka",region="iids",} 114.0
# HELP system_cpu_usage The "recent cpu usage" for the whole system
# TYPE system_cpu_usage gauge
system_cpu_usage{application="msa-eureka",region="iids",} 0.10567980731551899
# HELP jvm_gc_pause_seconds Time spent in GC pause
# TYPE jvm_gc_pause_seconds summary
jvm_gc_pause_seconds_count{action="end of major GC",application="msa-eureka",cause="Metadata GC Threshold",region="iids",} 2.0
jvm_gc_pause_seconds_sum{action="end of major GC",application="msa-eureka",cause="Metadata GC Threshold",region="iids",} 0.205
jvm_gc_pause_seconds_count{action="end of minor GC",application="msa-eureka",cause="Allocation Failure",region="iids",} 173.0
jvm_gc_pause_seconds_sum{action="end of minor GC",application="msa-eureka",cause="Allocation Failure",region="iids",} 1.23
# HELP jvm_gc_pause_seconds_max Time spent in GC pause
# TYPE jvm_gc_pause_seconds_max gauge
jvm_gc_pause_seconds_max{action="end of major GC",application="msa-eureka",cause="Metadata GC Threshold",region="iids",} 0.0
jvm_gc_pause_seconds_max{action="end of minor GC",application="msa-eureka",cause="Allocation Failure",region="iids",} 0.0
# HELP jvm_threads_states_threads The current number of threads having NEW state
# TYPE jvm_threads_states_threads gauge
jvm_threads_states_threads{application="msa-eureka",region="iids",state="blocked",} 0.0
jvm_threads_states_threads{application="msa-eureka",region="iids",state="new",} 0.0
jvm_threads_states_threads{application="msa-eureka",region="iids",state="runnable",} 6.0
jvm_threads_states_threads{application="msa-eureka",region="iids",state="terminated",} 0.0
jvm_threads_states_threads{application="msa-eureka",region="iids",state="waiting",} 23.0
jvm_threads_states_threads{application="msa-eureka",region="iids",state="timed-waiting",} 85.0
# HELP jvm_memory_used_bytes The amount of used memory
# TYPE jvm_memory_used_bytes gauge
jvm_memory_used_bytes{application="msa-eureka",area="nonheap",id="Metaspace",region="iids",} 6.206528E7
jvm_memory_used_bytes{application="msa-eureka",area="nonheap",id="Compressed Class Space",region="iids",} 7762904.0
jvm_memory_used_bytes{application="msa-eureka",area="nonheap",id="Code Cache",region="iids",} 2.5406912E7
jvm_memory_used_bytes{application="msa-eureka",area="heap",id="Tenured Gen",region="iids",} 3.6432368E7
jvm_memory_used_bytes{application="msa-eureka",area="heap",id="Survivor Space",region="iids",} 67592.0
jvm_memory_used_bytes{application="msa-eureka",area="heap",id="Eden Space",region="iids",} 2.7415784E7
# HELP jvm_gc_max_data_size_bytes Max size of old generation memory pool
# TYPE jvm_gc_max_data_size_bytes gauge
jvm_gc_max_data_size_bytes{application="msa-eureka",region="iids",} 1.78978816E8
# HELP jvm_threads_daemon_threads The current number of live daemon threads
# TYPE jvm_threads_daemon_threads gauge
jvm_threads_daemon_threads{application="msa-eureka",region="iids",} 110.0
# HELP tomcat_sessions_active_current_sessions
# TYPE tomcat_sessions_active_current_sessions gauge
tomcat_sessions_active_current_sessions{application="msa-eureka",region="iids",} 0.0
# HELP tomcat_sessions_alive_max_seconds
# TYPE tomcat_sessions_alive_max_seconds gauge
tomcat_sessions_alive_max_seconds{application="msa-eureka",region="iids",} 0.0
# HELP jvm_buffer_total_capacity_bytes An estimate of the total capacity of the buffers in this pool
# TYPE jvm_buffer_total_capacity_bytes gauge
jvm_buffer_total_capacity_bytes{application="msa-eureka",id="mapped",region="iids",} 0.0
jvm_buffer_total_capacity_bytes{application="msa-eureka",id="direct",region="iids",} 81920.0
# HELP jvm_classes_loaded_classes The number of classes that are currently loaded in the Java virtual machine
# TYPE jvm_classes_loaded_classes gauge
jvm_classes_loaded_classes{application="msa-eureka",region="iids",} 11983.0
# HELP jvm_gc_memory_allocated_bytes_total Incremented for an increase in the size of the young generation memory pool after one GC to before the next
# TYPE jvm_gc_memory_allocated_bytes_total counter
jvm_gc_memory_allocated_bytes_total{application="msa-eureka",region="iids",} 1.2440378656E10
# HELP process_uptime_seconds The uptime of the Java virtual machine
# TYPE process_uptime_seconds gauge
process_uptime_seconds{application="msa-eureka",region="iids",} 68904.59
# HELP jvm_memory_committed_bytes The amount of memory in bytes that is committed for the Java virtual machine to use
# TYPE jvm_memory_committed_bytes gauge
jvm_memory_committed_bytes{application="msa-eureka",area="nonheap",id="Metaspace",region="iids",} 6.549504E7
jvm_memory_committed_bytes{application="msa-eureka",area="nonheap",id="Compressed Class Space",region="iids",} 8388608.0
jvm_memory_committed_bytes{application="msa-eureka",area="nonheap",id="Code Cache",region="iids",} 2.6017792E7
jvm_memory_committed_bytes{application="msa-eureka",area="heap",id="Tenured Gen",region="iids",} 1.78978816E8
jvm_memory_committed_bytes{application="msa-eureka",area="heap",id="Survivor Space",region="iids",} 8912896.0
jvm_memory_committed_bytes{application="msa-eureka",area="heap",id="Eden Space",region="iids",} 7.1630848E7
# HELP jvm_buffer_memory_used_bytes An estimate of the memory that the Java virtual machine is using for this buffer pool
# TYPE jvm_buffer_memory_used_bytes gauge
......
1.5.2.配置Prometheus
https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/additional-scrape-config.md
1.创建文件
prometheus-additional.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
- job_name: mysql
scrape_interval: 15s
static_configs:
- targets: ['service-mysql-exporter.dev.svc.cluster.local:9104']
labels:
instance: mysqld
- job_name: msa-eureka
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-eureka-0.msa-eureka.pro:10001']
labels:
instance: msa-eureka-0
- targets: ['msa-eureka-1.msa-eureka.pro:10001']
labels:
instance: msa-eureka-1
- targets: ['msa-eureka-2.msa-eureka.pro:10001']
labels:
instance: msa-eureka-2
- job_name: msa-deploy-producer
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-deploy-producer.pro.svc.cluster.local:8911']
labels:
instance: spring-actuator
- job_name: msa-deploy-consumer
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-deploy-consumer.pro.svc.cluster.local:8912']
labels:
instance: spring-actuator
2.创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
2.
root@k8s-master1 prometheus]# kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run -oyaml > additional-scrape-configs.yaml
W1221 11:55:34.142707 6969 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
[root@k8s-master1 prometheus]# ll
total 332
-rw-r--r--. 1 root root 1507 Dec 21 11:55 additional-scrape-configs.yaml
-rw-r--r--. 1 root root 1027 Dec 21 11:55 prometheus-additional.yaml
[root@k8s-master1 prometheus]# kubectl apply -f additional-scrape-configs.yaml -n monitoring
secret/additional-scrape-configs created
3.
#prometheus-prometheus.yaml
[root@k8s-master1 kube-prometheus]# vim manifests/prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
labels:
prometheus: prometheus
spec:
replicas: 2
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
# 添加
additionalScrapeConfigs:
name: additional-scrape-configs
key: prometheus-additional.yaml
[root@k8s-master1 kube-prometheus]# kubectl apply -f manifests/prometheus-prometheus.yaml
Warning: resource prometheuses/k8s is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
prometheus.monitoring.coreos.com/k8s configured
# 此操作可不执行
[root@k8s-master manifests]# kubectl delete pod prometheus-k8s-0 -n monitoring
pod "prometheus-k8s-0" deleted
[root@k8s-master manifests]# kubectl delete pod prometheus-k8s-1 -n monitoring
pod "prometheus-k8s-1" deleted
3.测试
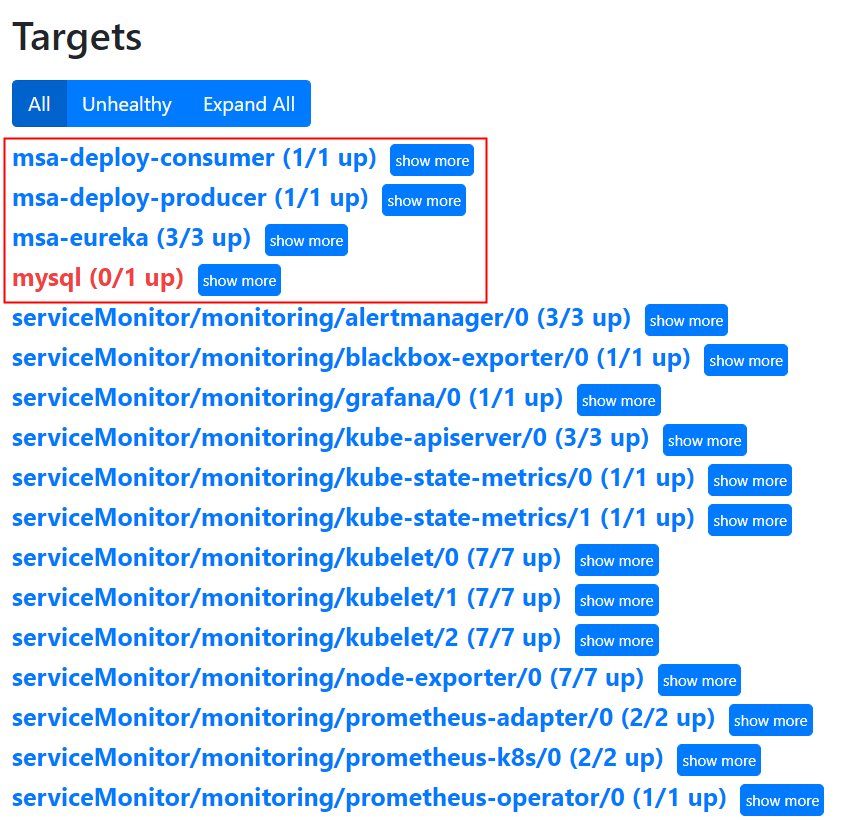
4.增加新配置(参考)
修改prometheus-additional.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- job_name: spring-boot-actuator
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator
- job_name: spring-boot
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator-1
1
2
3
4
5
6
7
[root@k8s-master prometheus]# kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run -oyaml > additional-scrape-configs.yaml
W1126 09:53:24.608990 62215 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
[root@k8s-master prometheus]# kubectl apply -f additional-scrape-configs.yaml -n monitoring
secret/additional-scrape-configs configured
1.5.3.配置Grafana
1
2
3
4
5
6
7
### 选择模板
# 4701
https://grafana.com/grafana/dashboards/4701
# 11955
https://grafana.com/grafana/dashboards/11955
2.Docker部署Prometheus
2.1.安装Prometheus
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
### 安装prometheus
# 创建目录
mkdir -p /ntms/prometheus
mkdir -p /ntms/prometheus/data
mkdir -p /ntms/prometheus/rules
chmod 777 -R /ntms/prometheus/data
# 创建配置文件
/ntms/prometheus/prometheus.yml
touch prometheus.yml
# 修改配置文件
/prometheus/prometheus/prometheus.yml
# prometheus.yml:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.17.88.22:9093
rule_files:
- "rules/*.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: alertmanager
scrape_interval: 5s
static_configs:
- targets: ['172.17.88.22:9093']
labels:
instance: alert
- job_name: spring-boot-actuator
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['172.51.216.81:30158']
labels:
instance: spring-actuator
- job_name: msa-deploy-producer
metrics_path: '/dproducer/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['gateway.k8s.com:31208']
labels:
instance: producer
- job_name: msa-deploy-consumer
metrics_path: '/dconsumer/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['gateway.k8s.com:31208']
labels:
instance: consumer
***************************************************************
### 运行docker
docker run -d --network host --name prometheus --restart=always \
-v /ntms/prometheus:/etc/prometheus \
-v /ntms/prometheus/data:/prometheus \
-e TZ=Asia/Shanghai \
prom/prometheus
### 访问地址
http://172.51.216.88:9090
2.2.安装Grafana
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 创建目录
mkdir -p /ntms/grafana/data
chmod 777 -R /ntms/grafana/data
### 运行docker
docker run -d --network host --name=grafana --restart=always \
-v /ntms/grafana/data:/var/lib/grafana \
grafana/grafana
### 访问地址
# grafana
http://172.51.216.88:3000
# 默认账号密码
用户名:admin
密码: admin
配置数据源