
一、概述
1.K8S监控指标
Kubernetes本身监控
- Node资源利用率 :一般生产环境几十个node,几百个node去监控
- Node数量 :一般能监控到node,就能监控到它的数量了,因为它是一个实例,一个node能跑多少个项目,也是需要去评估的,整体资源率在一个什么样的状态,什么样的值,所以需要根据项目,跑的资源利用率,还有值做一个评估的,比如再跑一个项目,需要多少资源。
- Pods数量(Node):其实也是一样的,每个node上都跑多少pod,不过默认一个node上能跑110个pod,但大多数情况下不可能跑这么多,比如一个128G的内存,32核cpu,一个java的项目,一个分配2G,也就是能跑50-60个,一般机器,pod也就跑几十个,很少很少超过100个。
- 资源对象状态 :比如pod,service,deployment,job这些资源状态,做一个统计。
Pod监控
- Pod数量(项目):你的项目跑了多少个pod的数量,大概的利益率是多少,好评估一下这个项目跑了多少个资源占有多少资源,每个pod占了多少资源。
- 容器资源利用率 :每个容器消耗了多少资源,用了多少CPU,用了多少内存
- 应用程序:这个就是偏应用程序本身的指标了,这个一般在我们运维很难拿到的,所以在监控之前呢,需要开发去给你暴露出来,这里有很多客户端的集成,客户端库就是支持很多语言的,需要让开发做一些开发量将它集成进去,暴露这个应用程序的想知道的指标,然后纳入监控,如果开发部配合,基本运维很难做到这一块,除非自己写一个客户端程序,通过shell/python能不能从外部获取内部的工作情况,如果这个程序提供API的话,这个很容易做到。
Prometheus监控K8S架构
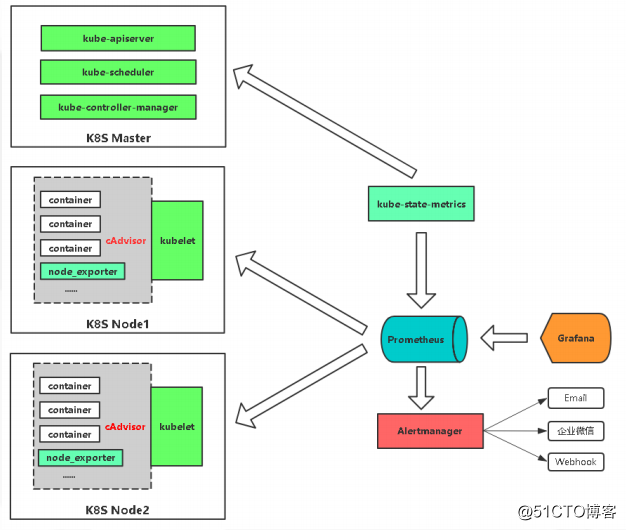
如果想监控node的资源,就可以放一个node_exporter,这是监控node资源的,node_exporter是Linux上的采集器,你放上去你就能采集到当前节点的CPU、内存、网络IO,等待都可以采集的。
如果想监控容器,k8s内部提供cAdvisor采集器,pod呀,容器都可以采集到这些指标,都是内置的,不需要单独部署,只知道怎么去访问这个Cadvisor就可以了。
如果想监控k8s资源对象,会部署一个kube-state-metrics这个服务,它会定时的API中获取到这些指标,帮你存取到Prometheus里,要是告警的话,通过Alertmanager发送给一些接收方,通过Grafana可视化展示。
2.Prometheus Operator
https://github.com/prometheus-operator/prometheus-operator
1.Kubernetes Operator
在Kubernetes的支持下,管理和伸缩Web应用、移动应用后端以及API服务都变得比较简单了。因为这些应用一般都是无状态的,所以Deployment这样的基础Kubernetes API对象就可以在无需附加操作的情况下,对应用进行伸缩和故障恢复了。
而对于数据库、缓存或者监控系统等有状态应用的管理,就是挑战了。这些系统需要掌握应用领域的知识,正确地进行伸缩和升级,当数据丢失或不可用的时候,要进行有效的重新配置。我们希望这些应用相关的运维技能可以编码到软件之中,从而借助Kubernetes 的能力,正确地运行和管理复杂应用。
Operator这种软件,使用TPR(第三方资源,现在已经升级为CRD)机制对Kubernetes API进行扩展,将特定应用的知识融入其中,让用户可以创建、配置和管理应用。与Kubernetes的内置资源一样,Operator操作的不是一个单实例应用,而是集群范围内的多实例。
2.Prometheus Operator
Kubernetes的Prometheus Operator为Kubernetes服务和Prometheus实例的部署和管理提供了简单的监控定义。
安装完毕后,Prometheus Operator提供了以下功能:
- 创建/毁坏。在Kubernetes namespace中更容易启动一个Prometheus实例,一个特定的应用程序或团队更容易使用的Operato。
- 简单配置。配Prometheus的基础东西,比如在Kubernetes的本地资源versions, persistence,retention policies和replicas。
- Target Services通过标签。基于常见的Kubernetes label查询,自动生成监控target配置;不需要学习Prometheus特定的配置语言。
Prometheus Operator架构如图1所示。
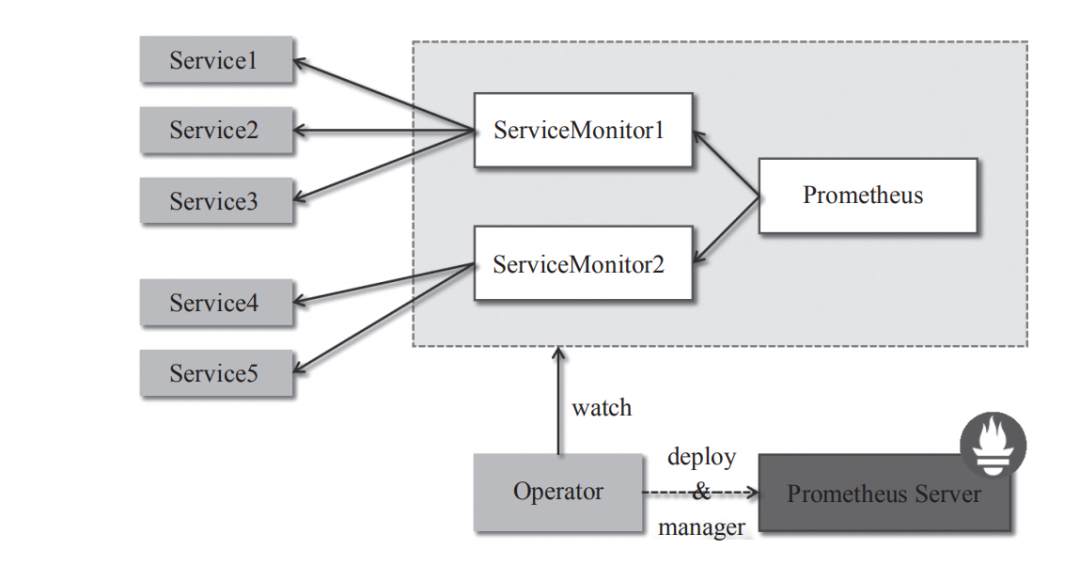
架构中的各组成部分以不同的资源方式运行在Kubernetes集群中,它们各自有不同的作用。
- Operator:Operator资源会根据自定义资源(Custom Resource Definition,CRD)来部署和管理Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus: Prometheus资源是声明性地描述Prometheus部署的期望状态。
- Prometheus Server: Operator根据自定义资源Prometheus类型中定义的内容而部署的Prometheus Server集群,这些自定义资源可以看作用来管理Prometheus Server 集群的StatefulSets资源。
- ServiceMonitor:ServiceMonitor也是一个自定义资源,它描述了一组被Prometheus监控的target列表。该资源通过标签来选取对应的Service Endpoint,让Prometheus Server通过选取的Service来获取Metrics信息。
- Service:Service资源主要用来对应Kubernetes集群中的Metrics Server Pod,提供给ServiceMonitor选取,让Prometheus Server来获取信息。简单说就是Prometheus监控的对象,例如Node Exporter Service、Mysql Exporter Service等。
- Alertmanager:Alertmanager也是一个自定义资源类型,由Operator根据资源描述内容来部署Alertmanager集群。
3.在Kubernetes上部署Prometheus的传统方式
本节详细介绍Kubernetes通过YAML文件方式部署Prometheus的过程,即按顺序部署了Prometheus、kube-state-metrics、node-exporter以及Grafana。图展示了各个组件的调用关系。
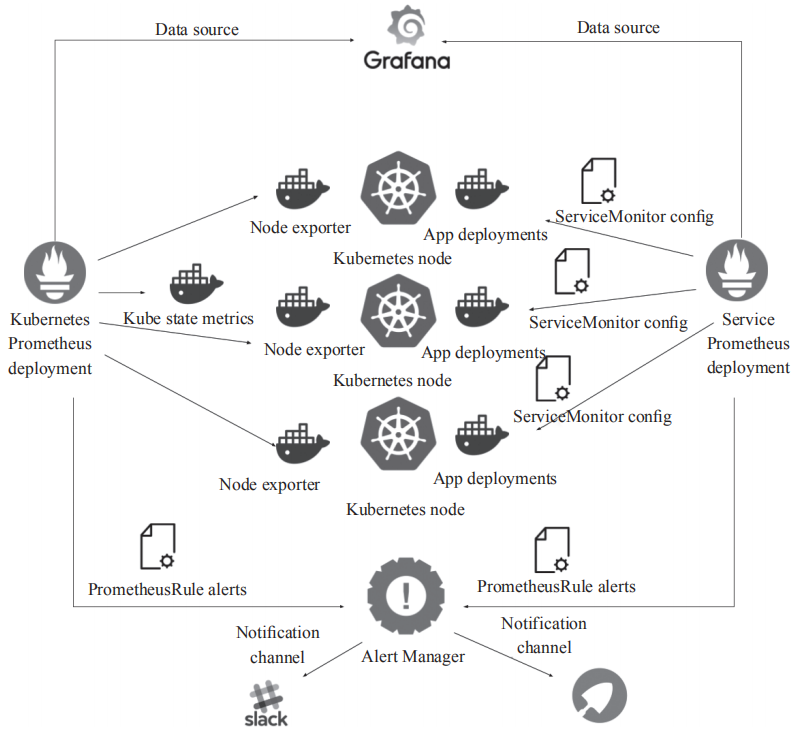
在Kubernetes Node上部署Node exporter,获取该节点物理机或者虚拟机的监控信息,在Kubernetes Master上部署kube-state-metrics获取Kubernetes集群的状态。所有信息汇聚到Prometheus进行处理和存储,然后通过Grafana进行展示。
3.kube-prometheus
kube-prometheus 是一整套监控解决方案,它使用 Prometheus 采集集群指标,Grafana 做展示,包含如下组件:
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs (k8s-prometheus-adapter)
- kube-state-metrics
- Grafana
1
2
3
4
5
6
7
# 地址
https://github.com/prometheus-operator
https://github.com/prometheus-operator/kube-prometheus
https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.8.0.tar.gz
https://github.com/kubernetes-monitoring/kubernetes-mixin
kube-prometheus是coreos专门为kubernetes封装的一套高可用的监控预警,方便用户直接安装使用。
kube-prometheus是用于kubernetes集群监控的,所以它预先配置了从所有Kubernetes组件中收集指标。除此之外,它还提供了一组默认的仪表板和警报规则。许多有用的仪表板和警报都来自于kubernetes-mixin项目,与此项目类似,它也提供了jsonnet,供用户根据自己的需求定制。
1.兼容性
The following versions are supported and work as we test against these versions in their respective branches. But note that other versions might work!
| kube-prometheus stack | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 | Kubernetes 1.21 | Kubernetes 1.22 |
|---|---|---|---|---|---|
release-0.6 |
✗ | ✔ | ✗ | ✗ | ✗ |
release-0.7 |
✗ | ✔ | ✔ | ✗ | ✗ |
release-0.8 |
✗ | ✗ | ✔ | ✔ | ✗ |
release-0.9 |
✗ | ✗ | ✗ | ✔ | ✔ |
main |
✗ | ✗ | ✗ | ✔ | ✔ |
2.快速启动
使用manifests目录下的配置创建监控:
1
2
3
4
5
# Create the namespace and CRDs, and then wait for them to be availble before creating the remaining resources
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
二、基础
1.kube-prometheus配置
1.1.manifests配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
[root@k8s-master manifests]# pwd
/k8s/prometheus/kube-prometheus/manifests
[root@k8s-master manifests]#
[root@k8s-master manifests]# ll
total 1756
-rw-r--r-- 1 root root 875 Nov 24 11:43 alertmanager-alertmanager.yaml
-rw-r--r-- 1 root root 515 Nov 24 11:43 alertmanager-podDisruptionBudget.yaml
-rw-r--r-- 1 root root 6831 Nov 24 11:43 alertmanager-prometheusRule.yaml
-rw-r--r-- 1 root root 1169 Nov 24 11:43 alertmanager-secret.yaml
-rw-r--r-- 1 root root 301 Nov 24 11:43 alertmanager-serviceAccount.yaml
-rw-r--r-- 1 root root 540 Nov 24 11:43 alertmanager-serviceMonitor.yaml
-rw-r--r-- 1 root root 577 Nov 24 11:43 alertmanager-service.yaml
-rw-r--r-- 1 root root 278 Nov 24 11:43 blackbox-exporter-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 287 Nov 24 11:43 blackbox-exporter-clusterRole.yaml
-rw-r--r-- 1 root root 1392 Nov 24 11:43 blackbox-exporter-configuration.yaml
-rw-r--r-- 1 root root 3080 Nov 24 11:43 blackbox-exporter-deployment.yaml
-rw-r--r-- 1 root root 96 Nov 24 11:43 blackbox-exporter-serviceAccount.yaml
-rw-r--r-- 1 root root 680 Nov 24 11:43 blackbox-exporter-serviceMonitor.yaml
-rw-r--r-- 1 root root 540 Nov 24 11:43 blackbox-exporter-service.yaml
-rw-r--r-- 1 root root 721 Nov 24 11:43 grafana-dashboardDatasources.yaml
-rw-r--r-- 1 root root 1406527 Nov 24 11:43 grafana-dashboardDefinitions.yaml
-rw-r--r-- 1 root root 625 Nov 24 11:43 grafana-dashboardSources.yaml
-rw-r--r-- 1 root root 8159 Nov 25 13:12 grafana-deployment.yaml
-rw-r--r-- 1 root root 86 Nov 24 11:43 grafana-serviceAccount.yaml
-rw-r--r-- 1 root root 398 Nov 24 11:43 grafana-serviceMonitor.yaml
-rw-r--r-- 1 root root 452 Nov 24 11:43 grafana-service.yaml
-rw-r--r-- 1 root root 3319 Nov 24 11:43 kube-prometheus-prometheusRule.yaml
-rw-r--r-- 1 root root 63571 Nov 24 11:43 kubernetes-prometheusRule.yaml
-rw-r--r-- 1 root root 6836 Nov 24 11:43 kubernetes-serviceMonitorApiserver.yaml
-rw-r--r-- 1 root root 440 Nov 24 11:43 kubernetes-serviceMonitorCoreDNS.yaml
-rw-r--r-- 1 root root 6355 Nov 24 11:43 kubernetes-serviceMonitorKubeControllerManager.yaml
-rw-r--r-- 1 root root 7171 Nov 24 11:43 kubernetes-serviceMonitorKubelet.yaml
-rw-r--r-- 1 root root 530 Nov 24 11:43 kubernetes-serviceMonitorKubeScheduler.yaml
-rw-r--r-- 1 root root 464 Nov 24 11:43 kube-state-metrics-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 1712 Nov 24 11:43 kube-state-metrics-clusterRole.yaml
-rw-r--r-- 1 root root 2957 Nov 24 11:43 kube-state-metrics-deployment.yaml
-rw-r--r-- 1 root root 1864 Nov 24 11:43 kube-state-metrics-prometheusRule.yaml
-rw-r--r-- 1 root root 280 Nov 24 11:43 kube-state-metrics-serviceAccount.yaml
-rw-r--r-- 1 root root 1011 Nov 24 11:43 kube-state-metrics-serviceMonitor.yaml
-rw-r--r-- 1 root root 580 Nov 24 11:43 kube-state-metrics-service.yaml
-rw-r--r-- 1 root root 444 Nov 24 11:43 node-exporter-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 461 Nov 24 11:43 node-exporter-clusterRole.yaml
-rw-r--r-- 1 root root 3020 Nov 24 11:43 node-exporter-daemonset.yaml
-rw-r--r-- 1 root root 12975 Nov 24 11:43 node-exporter-prometheusRule.yaml
-rw-r--r-- 1 root root 270 Nov 24 11:43 node-exporter-serviceAccount.yaml
-rw-r--r-- 1 root root 850 Nov 24 11:43 node-exporter-serviceMonitor.yaml
-rw-r--r-- 1 root root 492 Nov 24 11:43 node-exporter-service.yaml
-rw-r--r-- 1 root root 482 Nov 24 11:43 prometheus-adapter-apiService.yaml
-rw-r--r-- 1 root root 576 Nov 24 11:43 prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml
-rw-r--r-- 1 root root 494 Nov 24 11:43 prometheus-adapter-clusterRoleBindingDelegator.yaml
-rw-r--r-- 1 root root 471 Nov 24 11:43 prometheus-adapter-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 378 Nov 24 11:43 prometheus-adapter-clusterRoleServerResources.yaml
-rw-r--r-- 1 root root 409 Nov 24 11:43 prometheus-adapter-clusterRole.yaml
-rw-r--r-- 1 root root 1836 Nov 24 11:43 prometheus-adapter-configMap.yaml
-rw-r--r-- 1 root root 1804 Nov 24 11:43 prometheus-adapter-deployment.yaml
-rw-r--r-- 1 root root 515 Nov 24 11:43 prometheus-adapter-roleBindingAuthReader.yaml
-rw-r--r-- 1 root root 287 Nov 24 11:43 prometheus-adapter-serviceAccount.yaml
-rw-r--r-- 1 root root 677 Nov 24 11:43 prometheus-adapter-serviceMonitor.yaml
-rw-r--r-- 1 root root 501 Nov 24 11:43 prometheus-adapter-service.yaml
-rw-r--r-- 1 root root 447 Nov 24 11:43 prometheus-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 394 Nov 24 11:43 prometheus-clusterRole.yaml
-rw-r--r-- 1 root root 4930 Nov 24 11:43 prometheus-operator-prometheusRule.yaml
-rw-r--r-- 1 root root 715 Nov 24 11:43 prometheus-operator-serviceMonitor.yaml
-rw-r--r-- 1 root root 499 Nov 24 11:43 prometheus-podDisruptionBudget.yaml
-rw-r--r-- 1 root root 12732 Nov 24 11:43 prometheus-prometheusRule.yaml
-rw-r--r-- 1 root root 1418 Nov 25 14:12 prometheus-prometheus.yaml
-rw-r--r-- 1 root root 471 Nov 24 11:43 prometheus-roleBindingConfig.yaml
-rw-r--r-- 1 root root 1547 Nov 24 11:43 prometheus-roleBindingSpecificNamespaces.yaml
-rw-r--r-- 1 root root 366 Nov 24 11:43 prometheus-roleConfig.yaml
-rw-r--r-- 1 root root 2047 Nov 24 11:43 prometheus-roleSpecificNamespaces.yaml
-rw-r--r-- 1 root root 271 Nov 24 11:43 prometheus-serviceAccount.yaml
-rw-r--r-- 1 root root 531 Nov 24 11:43 prometheus-serviceMonitor.yaml
-rw-r--r-- 1 root root 558 Nov 24 11:43 prometheus-service.yaml
drwxr-xr-x 2 root root 4096 Nov 25 14:24 setup
[root@k8s-master manifests]#
[root@k8s-master manifests]# cd setup/
[root@k8s-master setup]# ll
total 1028
-rw-r--r-- 1 root root 60 Nov 24 11:43 0namespace-namespace.yaml
-rw-r--r-- 1 root root 122054 Nov 24 11:43 prometheus-operator-0alertmanagerConfigCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 247084 Nov 24 11:43 prometheus-operator-0alertmanagerCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 20907 Nov 24 11:43 prometheus-operator-0podmonitorCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 20077 Nov 24 11:43 prometheus-operator-0probeCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 327667 Nov 24 11:43 prometheus-operator-0prometheusCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 3618 Nov 24 11:43 prometheus-operator-0prometheusruleCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 21941 Nov 24 11:43 prometheus-operator-0servicemonitorCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 253551 Nov 24 11:43 prometheus-operator-0thanosrulerCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 471 Nov 24 11:43 prometheus-operator-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 1377 Nov 24 11:43 prometheus-operator-clusterRole.yaml
-rw-r--r-- 1 root root 2328 Nov 25 14:24 prometheus-operator-deployment.yaml
-rw-r--r-- 1 root root 285 Nov 24 11:43 prometheus-operator-serviceAccount.yaml
-rw-r--r-- 1 root root 515 Nov 24 11:43 prometheus-operator-service.yaml
1.2.修改镜像源
国外镜像源某些镜像无法拉取,我们这里修改prometheus-operator,prometheus,alertmanager,kube-state-metrics,node-exporter,prometheus-adapter的镜像源为国内镜像源。我这里使用的是中科大的镜像源。
1
2
3
4
5
6
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' setup/prometheus-operator-deployment.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' prometheus-prometheus.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' alertmanager-alertmanager.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' kube-state-metrics-deployment.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' node-exporter-daemonset.yaml
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' prometheus-adapter-deployment.yaml
1.3.service
1.prometheus的service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[root@k8s-master manifests]# vim prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30090 # 新增
type: NodePort # 新增
selector:
app: prometheus
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
prometheus: k8s
sessionAffinity: ClientIP
2.alertmanager的service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[root@k8s-master manifests]# vim alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
spec:
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30093 # 新增
type: NodePort # 新增
selector:
alertmanager: main
app: alertmanager
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: ClientIP
3.grafana的service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
[root@k8s-master manifests]# vim grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 7.5.4
name: grafana
namespace: monitoring
spec:
ports:
- name: http
port: 3000
targetPort: http
nodePort: 32000 # 新增
type: NodePort # 新增
selector:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
1.4.修改副本数
默认alertmanager副本数为3,prometheus副本数为2,grafana副本数为1。这是官方基于高可用考虑的
1.alertmanager
1
vi alertmanager-alertmanager.yaml
2.prometheus
1
vi prometheus-prometheus.yaml
3.grafana
1
vi grafana-deployment.yaml
2.kube-prometheus数据持久化
2.1.Prometheus数据持久化
1.修改文件 manifests/prometheus-prometheus.yaml
1
2
3
4
5
6
7
8
9
10
#-----storage-----
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
#-----------------
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 完整配置
# prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
externalLabels: {}
#-----storage-----
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
#-----------------
image: quay.io/prometheus/prometheus:v2.26.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.26.0
在修改yaml文件之后执行kubectl apply -f manifests/prometheus-prometheus.yaml命令,会自动创建两个指定大小的pv卷,因为会为prometheus的备份(prometheus-k8s-0,prometheus-k8s-1)也创建一个pv(我是用的是ceph-rbd,也可以换成其他的文件系统),但是pv卷创建之后,无法修改,所以最好先考虑好合适的参数配置,比如访问模式和容量大小。在下次重新apply prometheus-prometheus.yaml时,数据会存到已经创建的pv卷中。
2.存储时长配置为10天(无效)
修改文件manifests/setup/prometheus-operator-deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# prometheus-operator-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.47.0
name: prometheus-operator
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/part-of: kube-prometheus
template:
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.47.0
spec:
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --prometheus-config-reloader=quay.io/prometheus-operator/prometheus-config-reloader:v0.47.0
- storage.tsdb.retention.time=10d # 在这添加time参数
image: quay.io/prometheus-operator/prometheus-operator:v0.47.0
name: prometheus-operator
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
- args:
- --logtostderr
- --secure-listen-address=:8443
- --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305
- --upstream=http://127.0.0.1:8080/
image: quay.io/brancz/kube-rbac-proxy:v0.8.0
name: kube-rbac-proxy
ports:
- containerPort: 8443
name: https
resources:
limits:
cpu: 20m
memory: 40Mi
requests:
cpu: 10m
memory: 20Mi
securityContext:
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65532
nodeSelector:
kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: prometheus-operator
注意:参数名为storage.tsdb.retention.time=10d,我之前使用的是--storage.tsdb.retention.time=10d,apply之后提示flag 提供了但未定义。
2.2.修改存储数据时间
prometheus operator数据保留天数,根据官方文档的说明,默认prometheus operator数据存储的时间为1d,这个时候无论你prometheus operator如何进行持久化,都没有作用,因为数据只保留了1天,那么你是无法看到更多天数的数据
官方文档可以配置的说明
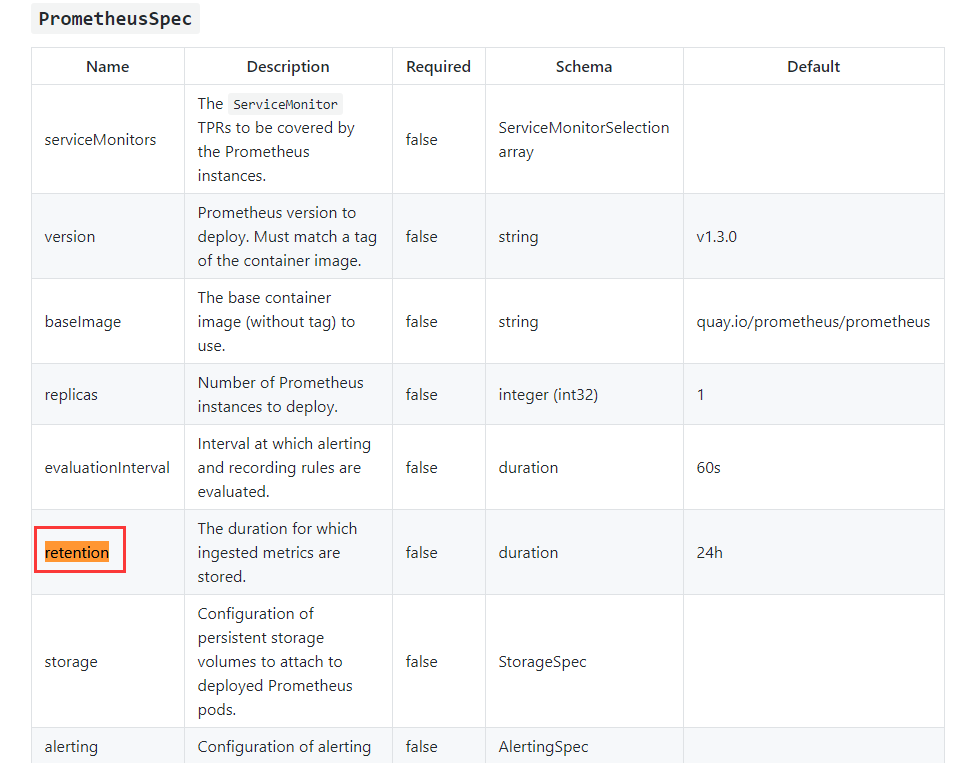
实际上修改prometheus operator时间是通过retention参数进行修改,上面也提示了在prometheus.spec下填写
修改方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
[root@k8s-master manifests]# pwd
/k8s/monitoring/prometheus/kube-prometheus-0.8.0/manifests
[root@k8s-master manifests]# vim prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
......
spec:
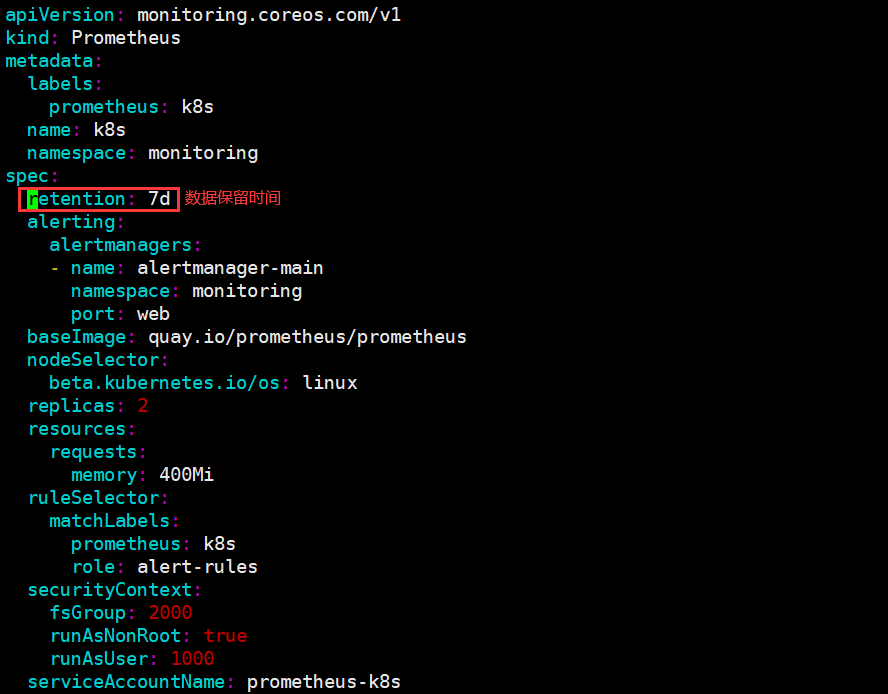
retention: 7d # 数据保留时间
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
externalLabels: {}
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 40Gi
image: quay.mirrors.ustc.edu.cn/prometheus/prometheus:v2.26.0
# 如果已经安装了可以直接修改prometheus-prometheus.yaml 然后通过kubectl apply -f 刷新即可
# 修改完毕后检查pod运行状态是否正常
# 接下来可以访问grafana或者prometheus ui进行检查 (我这里修改完毕后等待2天,检查数据是否正常)
2.3.Grafana配置持久化
1.创建grafana-pvc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
storageClassName: rook-cephfs
然后在grafana-deployment.yaml将emptydir存储方式改为pvc方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#- emptyDir: {}
# name: grafana-storage
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
- name: grafana-datasources
secret:
secretName: grafana-datasources
- configMap:
name: grafana-dashboards
name: grafana-dashboards
- configMap:
name: grafana-dashboard-apiserver
name: grafana-dashboard-apiserver
- configMap:
name: grafana-dashboard-controller-manager
........
文件存储(CephFS):适用Deployment,多个Pod文件共享;
3.promethus operator监控扩展
3.1.ServiceMonitor
为了能够自动化的管理Prometheus的配置,Prometheus Operator使用了自定义资源类型ServiceMonitor来描述监控对象的信息。
serviceMonitor 是通过对service 获取数据的一种方式。
- promethus-operator可以通过serviceMonitor 自动识别带有某些 label 的service ,并从这些service 获取数据。
- serviceMonitor 也是由promethus-operator 自动发现的。
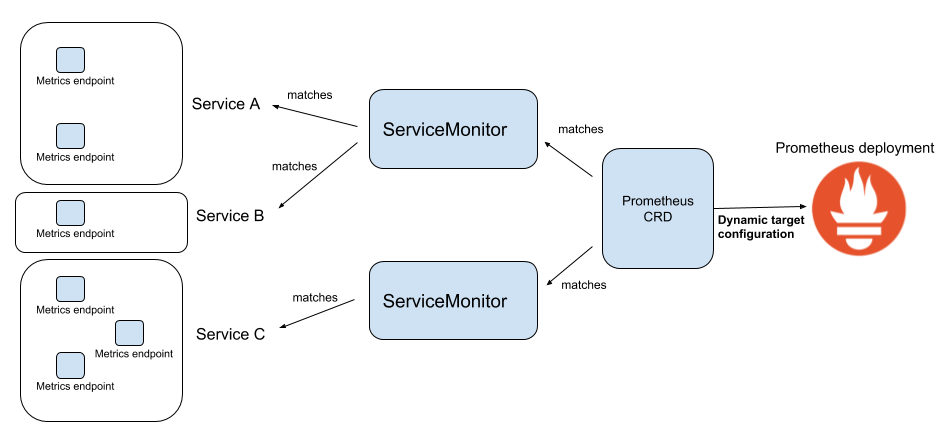
1.k8s集群内部服务监控
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[root@k8s-m1 ~]# cat ServiceMonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: xxx-exporter
name: xxx
namespace: prometheus
spec:
endpoints:
- interval: 15s
port: xxx-exporter
jobLabel: xxx-exporter-monitor
namespaceSelector:
matchNames:
- monitor #目标服务的namespaces
selector:
matchLabels:
k8s-app: xx-exporter #目标服务的labels
1
2
namespaceSelector:
any: true # 选择所有的namespace
2.监控集群外部的exporter通Endpoints实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 为外部 exporter 服务设置 service
kind: Service
apiVersion: v1
metadata:
namespace: monitor
name: service-mysql-xx
labels:
app: service-mysql-xx
spec:
ports:
- protocol: TCP
port: 9xx
targetPort: 9xx
type: ClusterIP
clusterIP: None
---
kind: Endpoints
apiVersion: v1
metadata:
namespace: monitor
name: service-mysql-xx
labels:
app: service-mysql-xx
subsets:
- addresses:
- ip: x.x.x.x
ports:
- protocol: TCP
port: 9xxx
ServiceMonitor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: service-mysql-xx
labels:
app: service-mysql-xx
spec:
selector:
matchLabels:
app: service-mysql-xx
namespaceSelector:
matchNames:
- monitor
endpoints:
- port: metrics
interval: 10s
honorLabels: true
3.2.传统配置(Additional Scrape Configuration)
https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/additional-scrape-config.md
4.报警
三、实践
1.安装kube-prometheus
1
2
3
4
5
6
7
# Create the namespace and CRDs, and then wait for them to be available before creating the remaining resources
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
1.安装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
[root@k8s-master manifests]# cd kube-prometheus
# 1.创建prometheus-operator
[root@k8s-master kube-prometheus]# kubectl create -f manifests/setup
namespace/monitoring created
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
service/prometheus-operator created
serviceaccount/prometheus-operator created
# 查看
[root@k8s-master kube-prometheus]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/prometheus-operator-7775c66ccf-qdg56 2/2 Running 0 63s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus-operator ClusterIP None <none> 8443/TCP 63s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-operator 1/1 1 1 63s
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-operator-7775c66ccf 1 1 1 63s
# 检查
[root@k8s-master kube-prometheus]# until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
No resources found
# 2.创建prometheus
[root@k8s-master kube-prometheus]# kubectl create -f manifests/
alertmanager.monitoring.coreos.com/main created
poddisruptionbudget.policy/alertmanager-main created
prometheusrule.monitoring.coreos.com/alertmanager-main-rules created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager created
clusterrole.rbac.authorization.k8s.io/blackbox-exporter created
clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created
configmap/blackbox-exporter-configuration created
deployment.apps/blackbox-exporter created
service/blackbox-exporter created
serviceaccount/blackbox-exporter created
servicemonitor.monitoring.coreos.com/blackbox-exporter created
secret/grafana-datasources created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-statefulset created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
prometheusrule.monitoring.coreos.com/kube-prometheus-rules created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
prometheusrule.monitoring.coreos.com/node-exporter-rules created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
prometheusrule.monitoring.coreos.com/prometheus-operator-rules created
servicemonitor.monitoring.coreos.com/prometheus-operator created
poddisruptionbudget.policy/prometheus-k8s created
prometheus.monitoring.coreos.com/k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-k8s created
Error from server (AlreadyExists): error when creating "manifests/prometheus-adapter-apiService.yaml": apiservices.apiregistration.k8s.io "v1beta1.metrics.k8s.io" already exists
Error from server (AlreadyExists): error when creating "manifests/prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml": clusterroles.rbac.authorization.k8s.io "system:aggregated-metrics-reader" already exists
# 查看
[root@k8s-master prometheus]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 119m
pod/alertmanager-main-1 2/2 Running 0 119m
pod/alertmanager-main-2 2/2 Running 0 119m
pod/blackbox-exporter-55c457d5fb-78bs9 3/3 Running 0 119m
pod/grafana-9df57cdc4-gnbkp 1/1 Running 0 119m
pod/kube-state-metrics-76f6cb7996-cfq79 2/3 ImagePullBackOff 0 62m
pod/node-exporter-g5vqs 2/2 Running 0 119m
pod/node-exporter-ks6h7 2/2 Running 0 119m
pod/node-exporter-s8c4m 2/2 Running 0 119m
pod/node-exporter-tlmp6 2/2 Running 0 119m
pod/prometheus-adapter-59df95d9f5-jdpzp 1/1 Running 0 119m
pod/prometheus-adapter-59df95d9f5-k6t66 1/1 Running 0 119m
pod/prometheus-k8s-0 2/2 Running 1 119m
pod/prometheus-k8s-1 2/2 Running 1 119m
pod/prometheus-operator-7775c66ccf-qdg56 2/2 Running 0 127m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.96.148.16 <none> 9093/TCP 119m
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 119m
service/blackbox-exporter ClusterIP 10.102.106.12 <none> 9115/TCP,19115/TCP 119m
service/grafana ClusterIP 10.96.45.54 <none> 3000/TCP 119m
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 119m
service/node-exporter ClusterIP None <none> 9100/TCP 119m
service/prometheus-adapter ClusterIP 10.108.127.216 <none> 443/TCP 119m
service/prometheus-k8s ClusterIP 10.100.120.200 <none> 9090/TCP 119m
service/prometheus-operated ClusterIP None <none> 9090/TCP 119m
service/prometheus-operator ClusterIP None <none> 8443/TCP 127m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 4 4 4 4 4 kubernetes.io/os=linux 119m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/blackbox-exporter 1/1 1 1 119m
deployment.apps/grafana 1/1 1 1 119m
deployment.apps/kube-state-metrics 0/1 1 0 119m
deployment.apps/prometheus-adapter 2/2 2 2 119m
deployment.apps/prometheus-operator 1/1 1 1 127m
NAME DESIRED CURRENT READY AGE
replicaset.apps/blackbox-exporter-55c457d5fb 1 1 1 119m
replicaset.apps/grafana-9df57cdc4 1 1 1 119m
replicaset.apps/kube-state-metrics-76f6cb7996 1 1 0 119m
replicaset.apps/prometheus-adapter-59df95d9f5 2 2 2 119m
replicaset.apps/prometheus-operator-7775c66ccf 1 1 1 127m
NAME READY AGE
statefulset.apps/alertmanager-main 3/3 119m
statefulset.apps/prometheus-k8s 2/2 119m
[root@k8s-master prometheus]# until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
NAMESPACE NAME AGE
monitoring alertmanager 119m
monitoring blackbox-exporter 119m
monitoring coredns 119m
monitoring grafana 119m
monitoring kube-apiserver 119m
monitoring kube-controller-manager 119m
monitoring kube-scheduler 119m
monitoring kube-state-metrics 119m
monitoring kubelet 119m
monitoring node-exporter 119m
monitoring prometheus-adapter 119m
monitoring prometheus-k8s 119m
monitoring prometheus-operator 119m
[root@k8s-master prometheus]# kubectl get pod -n monitoring -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-main-0 2/2 Running 0 3h13m 10.244.36.95 k8s-node1 <none> <none>
alertmanager-main-1 2/2 Running 0 3h13m 10.244.36.121 k8s-node1 <none> <none>
alertmanager-main-2 2/2 Running 0 3h13m 10.244.36.92 k8s-node1 <none> <none>
blackbox-exporter-55c457d5fb-78bs9 3/3 Running 0 3h13m 10.244.36.104 k8s-node1 <none> <none>
grafana-9df57cdc4-gnbkp 1/1 Running 0 3h13m 10.244.36.123 k8s-node1 <none> <none>
kube-state-metrics-76f6cb7996-cfq79 3/3 Running 0 136m 10.244.107.193 k8s-node3 <none> <none>
node-exporter-g5vqs 2/2 Running 0 3h13m 172.51.216.84 k8s-node3 <none> <none>
node-exporter-ks6h7 2/2 Running 0 3h13m 172.51.216.81 k8s-master <none> <none>
node-exporter-s8c4m 2/2 Running 0 3h13m 172.51.216.82 k8s-node1 <none> <none>
node-exporter-tlmp6 2/2 Running 0 3h13m 172.51.216.83 k8s-node2 <none> <none>
prometheus-adapter-59df95d9f5-jdpzp 1/1 Running 0 3h13m 10.244.36.125 k8s-node1 <none> <none>
prometheus-adapter-59df95d9f5-k6t66 1/1 Running 0 3h13m 10.244.169.133 k8s-node2 <none> <none>
prometheus-k8s-0 2/2 Running 1 3h13m 10.244.169.143 k8s-node2 <none> <none>
prometheus-k8s-1 2/2 Running 1 3h13m 10.244.36.86 k8s-node1 <none> <none>
prometheus-operator-7775c66ccf-qdg56 2/2 Running 0 3h21m 10.244.36.89 k8s-node1 <none> <none>
2.镜像拉取处理
1
2
3
4
5
6
7
8
9
10
11
12
13
# 不能拉取的镜像
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0
# 处理方式
docker pull bitnami/kube-state-metrics:2.0.0
docker tag bitnami/kube-state-metrics:2.0.0 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0
# 参考地址
https://hub.docker.com/r/bitnami/kube-state-metrics
https://github.com/kubernetes/kube-state-metrics
https://github.com/kubernetes/kube-state-metrics
At most, 5 kube-state-metrics and 5 kubernetes releases will be recorded below.
| kube-state-metrics | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 | Kubernetes 1.21 | Kubernetes 1.22 |
|---|---|---|---|---|---|
| v1.9.8 | - | - | - | - | - |
| v2.0.0 | -/✓ | ✓ | ✓ | -/✓ | -/✓ |
| v2.1.1 | -/✓ | ✓ | ✓ | ✓ | -/✓ |
| v2.2.4 | -/✓ | ✓ | ✓ | ✓ | ✓ |
| master | -/✓ | ✓ | ✓ | ✓ | ✓ |
✓Fully supported version range.-The Kubernetes cluster has features the client-go library can’t use (additional API objects, deprecated APIs, etc).
3.创建Ingress
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# prometheus-ing.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ing
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: prometheus.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
- host: grafana.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
- host: alertmanager.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
[root@k8s-master prometheus]# kubectl apply -f prometheus-ing.yaml
ingress.networking.k8s.io/prometheus-ing created
[root@k8s-master prometheus]# kubectl get ing -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
prometheus-ing <none> prometheus.k8s.com,grafana.k8s.com,alertmanager.k8s.com 80 14s
在本机添加域名解析
C:\Windows\System32\drivers\etc
在hosts文件添加域名解析(master主机的iP地址)
172.51.216.81 prometheus.k8s.com
172.51.216.81 grafana.k8s.com
172.51.216.81 alertmanager.k8s.com
[root@k8s-master prometheus]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.97.245.122 <none> 80:31208/TCP,443:32099/TCP 71d
ingress-nginx-controller NodePort 10.101.238.213 <none> 80:30743/TCP,443:31410/TCP 71d
ingress-nginx-controller-admission ClusterIP 10.100.142.101 <none> 443/TCP 71d
# ingress地址
# 在本机浏览器输入:
http://prometheus.k8s.com:31208/
http://alertmanager.k8s.com:31208/
http://grafana.k8s.com:31208/
admin/admin
2.kube-prometheus数据持久化
2.1.Prometheus数据持久化
1.查看存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
# 查看prometheus
[root@k8s-master manifests]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/prometheus-k8s-0 2/2 Running 1 26h
pod/prometheus-k8s-1 2/2 Running 1 26h
NAME READY AGE
statefulset.apps/prometheus-k8s 2/2 26h
# 查看statefulset.apps/prometheus-k8s
[root@k8s-master manifests]# kubectl edit sts prometheus-k8s -n monitoring
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: apps/v1
kind: StatefulSet
metadata:
......
spec:
......
template:
......
spec:
containers:
- args:
- --web.console.templates=/etc/prometheus/consoles
- --web.console.libraries=/etc/prometheus/console_libraries
- --config.file=/etc/prometheus/config_out/prometheus.env.yaml
- --storage.tsdb.path=/prometheus
# 存储时长
- --storage.tsdb.retention.time=24h
- --web.enable-lifecycle
- --storage.tsdb.no-lockfile
- --web.route-prefix=/
image: quay.io/prometheus/prometheus:v2.26.0
imagePullPolicy: IfNotPresent
name: prometheus
ports:
- containerPort: 9090
name: web
protocol: TCP
......
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: config-out
readOnly: true
- mountPath: /etc/prometheus/certs
name: tls-assets
readOnly: true
- mountPath: /prometheus
name: prometheus-k8s-db
- mountPath: /etc/prometheus/rules/prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
......
volumes:
- name: config
secret:
defaultMode: 420
secretName: prometheus-k8s
- name: tls-assets
secret:
defaultMode: 420
secretName: prometheus-k8s-tls-assets
# 存储
- emptyDir: {}
name: config-out
- configMap:
defaultMode: 420
name: prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
# 存储
- emptyDir: {}
name: prometheus-k8s-db
2.修改文件 manifests/prometheus-prometheus.yaml
1
2
3
4
5
6
7
8
9
10
#-----storage-----
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
#-----------------
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 完整配置
# prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
externalLabels: {}
#-----storage-----
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
#-----------------
image: quay.io/prometheus/prometheus:v2.26.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.26.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 重新创建
[root@k8s-master manifests]# kubectl apply -f prometheus-prometheus.yaml
Warning: resource prometheuses/k8s is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
prometheus.monitoring.coreos.com/k8s configured
[root@k8s-master manifests]# kubectl get pvc -n monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-d14953b7-22b4-42e7-88a6-2a869f1f729c 10Gi RWO rook-ceph-block 91s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-05f94b8e-b22b-4418-9887-d0210df8e79d 10Gi RWO rook-ceph-block 91s
[root@k8s-master manifests]# kubectl get pv -n monitoring
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-05f94b8e-b22b-4418-9887-d0210df8e79d 10Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-1 rook-ceph-block 103s
pvc-d14953b7-22b4-42e7-88a6-2a869f1f729c 10Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-0 rook-ceph-block 102s
3.存储时长配置为10天
修改文件manifests/setup/prometheus-operator-deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# prometheus-operator-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.47.0
name: prometheus-operator
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/part-of: kube-prometheus
template:
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.47.0
spec:
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --prometheus-config-reloader=quay.io/prometheus-operator/prometheus-config-reloader:v0.47.0
- storage.tsdb.retention.time=10d # 在这添加time参数
image: quay.io/prometheus-operator/prometheus-operator:v0.47.0
name: prometheus-operator
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
- args:
- --logtostderr
- --secure-listen-address=:8443
- --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305
- --upstream=http://127.0.0.1:8080/
image: quay.io/brancz/kube-rbac-proxy:v0.8.0
name: kube-rbac-proxy
ports:
- containerPort: 8443
name: https
resources:
limits:
cpu: 20m
memory: 40Mi
requests:
cpu: 10m
memory: 20Mi
securityContext:
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65532
nodeSelector:
kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: prometheus-operator
注意:参数名为storage.tsdb.retention.time=10d,我之前使用的是--storage.tsdb.retention.time=10d,apply之后提示flag 提供了但未定义。
1
2
3
[root@k8s-master setup]# kubectl apply -f prometheus-operator-deployment.yaml
Warning: resource deployments/prometheus-operator is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
deployment.apps/prometheus-operator configured
4.查看存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 查看statefulset.apps/prometheus-k8s
[root@k8s-master manifests]# kubectl edit sts prometheus-k8s -n monitoring
[root@k8s-master setup]# kubectl edit sts prometheus-k8s -n monitoring
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: apps/v1
kind: StatefulSet
metadata:
......
spec:
......
spec:
containers:
- args:
- --web.console.templates=/etc/prometheus/consoles
- --web.console.libraries=/etc/prometheus/console_libraries
- --config.file=/etc/prometheus/config_out/prometheus.env.yaml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention.time=24h
- --web.enable-lifecycle
- --storage.tsdb.no-lockfile
- --web.route-prefix=/
image: quay.io/prometheus/prometheus:v2.26.0
......
volumes:
- name: config
secret:
defaultMode: 420
secretName: prometheus-k8s
- name: tls-assets
secret:
defaultMode: 420
secretName: prometheus-k8s-tls-assets
- emptyDir: {}
name: config-out
- configMap:
defaultMode: 420
name: prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
# 修改后的存储
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
name: prometheus-k8s-db
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: rook-ceph-block
volumeMode: Filesystem
status:
phase: Pending
2.2.Grafana配置持久化
1.创建grafana-pvc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
storageClassName: rook-cephfs
resources:
requests:
storage: 5Gi
1
2
3
4
5
6
7
8
9
10
11
[root@k8s-master prometheus]# kubectl apply -f grafana-pvc.yaml
persistentvolumeclaim/grafana-pvc created
[root@k8s-master prometheus]# kubectl get pvc -n monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
grafana-pvc Bound pvc-952480c5-6702-488b-b1ce-d4e39a17a137 5Gi RWX rook-cephfs 26s
[root@k8s-master prometheus]# kubectl get pv -n monitoring
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-952480c5-6702-488b-b1ce-d4e39a17a137 5Gi RWX Delete Bound monitoring/grafana-pvc rook-cephfs 114s
2.重新创建grafana
在grafana-deployment.yaml将emptydir存储方式改为pvc方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# grafana-deployment.yaml
volumes:
#- emptyDir: {}
# name: grafana-storage
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
- name: grafana-datasources
secret:
secretName: grafana-datasources
- configMap:
name: grafana-dashboards
name: grafana-dashboards
- configMap:
name: grafana-dashboard-apiserver
name: grafana-dashboard-apiserver
- configMap:
name: grafana-dashboard-controller-manager
........
1
2
[root@k8s-master manifests]# kubectl apply -f grafana-deployment.yaml
Warning: resource deployments/grafana is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
3.测试
删除Grafana的Pod后,原密码有效,原来配置存在。
3.Spring Boot监控
微服务:msa-ext-prometheus
3.1.创建服务
1.创建msa-ext-prometheus
msa-ext-prometheus.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
apiVersion: v1
kind: Service
metadata:
namespace: dev
name: msa-ext-prometheus
labels:
app: msa-ext-prometheus
spec:
type: NodePort
ports:
- port: 8158
name: msa-ext-prometheus
targetPort: 8158
nodePort: 30158 #对外暴露30158端口
selector:
app: msa-ext-prometheus
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: dev
name: msa-ext-prometheus
spec:
replicas: 3
selector:
matchLabels:
app: msa-ext-prometheus
template:
metadata:
labels:
app: msa-ext-prometheus
spec:
imagePullSecrets:
- name: harborsecret #对应创建私有镜像密钥Secret
containers:
- name: msa-ext-prometheus
image: 172.51.216.85:8888/springcloud/msa-ext-prometheus:1.0.0
imagePullPolicy: Always #如果省略imagePullPolicy,策略为IfNotPresent
ports:
- containerPort: 8158
env:
- name: ACTIVE
value: "-Dspring.profiles.active=k8s"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
[root@k8s-master prometheus]# kubectl apply -f msa-ext-prometheus.yaml
service/msa-ext-prometheus created
deployment.apps/msa-ext-prometheus created
[root@k8s-master prometheus]# kubectl get all -n dev | grep msa-ext-prometheus
pod/msa-ext-prometheus-6599578495-dhblt 1/1 Running 0 44s
pod/msa-ext-prometheus-6599578495-srxs4 1/1 Running 0 44s
pod/msa-ext-prometheus-6599578495-z6l7d 1/1 Running 0 44s
service/msa-ext-prometheus NodePort 10.98.140.165 <none> 8158:30158/TCP 44s
deployment.apps/msa-ext-prometheus 3/3 3 3 44s
replicaset.apps/msa-ext-prometheus-6599578495 3 3 3 44s
# 访问 http://172.51.216.81:30158/actuator
{"_links":{"self":{"href":"http://172.51.216.81:30158/actuator","templated":false},"beans":{"href":"http://172.51.216.81:30158/actuator/beans","templated":false},"caches":{"href":"http://172.51.216.81:30158/actuator/caches","templated":false},"caches-cache":{"href":"http://172.51.216.81:30158/actuator/caches/{cache}","templated":true},"health":{"href":"http://172.51.216.81:30158/actuator/health","templated":false},"health-path":{"href":"http://172.51.216.81:30158/actuator/health/{*path}","templated":true},"info":{"href":"http://172.51.216.81:30158/actuator/info","templated":false},"conditions":{"href":"http://172.51.216.81:30158/actuator/conditions","templated":false},"configprops":{"href":"http://172.51.216.81:30158/actuator/configprops","templated":false},"env-toMatch":{"href":"http://172.51.216.81:30158/actuator/env/{toMatch}","templated":true},"env":{"href":"http://172.51.216.81:30158/actuator/env","templated":false},"loggers":{"href":"http://172.51.216.81:30158/actuator/loggers","templated":false},"loggers-name":{"href":"http://172.51.216.81:30158/actuator/loggers/{name}","templated":true},"heapdump":{"href":"http://172.51.216.81:30158/actuator/heapdump","templated":false},"threaddump":{"href":"http://172.51.216.81:30158/actuator/threaddump","templated":false},"prometheus":{"href":"http://172.51.216.81:30158/actuator/prometheus","templated":false},"metrics-requiredMetricName":{"href":"http://172.51.216.81:30158/actuator/metrics/{requiredMetricName}","templated":true},"metrics":{"href":"http://172.51.216.81:30158/actuator/metrics","templated":false},"scheduledtasks":{"href":"http://172.51.216.81:30158/actuator/scheduledtasks","templated":false},"mappings":{"href":"http://172.51.216.81:30158/actuator/mappings","templated":false}}}
# 访问 http://172.51.216.81:30158/actuator/prometheus
# HELP jvm_threads_daemon_threads The current number of live daemon threads
# TYPE jvm_threads_daemon_threads gauge
jvm_threads_daemon_threads{application="springboot-prometheus",region="iids",} 16.0
# HELP jvm_buffer_memory_used_bytes An estimate of the memory that the Java virtual machine is using for this buffer pool
# TYPE jvm_buffer_memory_used_bytes gauge
jvm_buffer_memory_used_bytes{application="springboot-prometheus",id="mapped",region="iids",} 0.0
jvm_buffer_memory_used_bytes{application="springboot-prometheus",id="direct",region="iids",} 81920.0
# HELP jvm_threads_peak_threads The peak live thread count since the Java virtual machine started or peak was reset
# TYPE jvm_threads_peak_threads gauge
jvm_threads_peak_threads{application="springboot-prometheus",region="iids",} 20.0
# HELP system_cpu_usage The "recent cpu usage" for the whole system
# TYPE system_cpu_usage gauge
system_cpu_usage{application="springboot-prometheus",region="iids",} 0.10248447204968944
# HELP jvm_gc_pause_seconds Time spent in GC pause
# TYPE jvm_gc_pause_seconds summary
jvm_gc_pause_seconds_count{action="end of major GC",application="springboot-prometheus",cause="Metadata GC Threshold",region="iids",} 1.0
jvm_gc_pause_seconds_sum{action="end of major GC",application="springboot-prometheus",cause="Metadata GC Threshold",region="iids",} 0.077
jvm_gc_pause_seconds_count{action="end of minor GC",application="springboot-prometheus",cause="Allocation Failure",region="iids",} 2.0
jvm_gc_pause_seconds_sum{action="end of minor GC",application="springboot-prometheus",cause="Allocation Failure",region="iids",} 0.048
# HELP jvm_gc_pause_seconds_max Time spent in GC pause
# TYPE jvm_gc_pause_seconds_max gauge
jvm_gc_pause_seconds_max{action="end of major GC",application="springboot-prometheus",cause="Metadata GC Threshold",region="iids",} 0.077
jvm_gc_pause_seconds_max{action="end of minor GC",application="springboot-prometheus",cause="Allocation Failure",region="iids",} 0.026
# HELP http_server_requests_seconds
# TYPE http_server_requests_seconds summary
http_server_requests_seconds_count{application="springboot-prometheus",exception="None",method="GET",outcome="CLIENT_ERROR",region="iids",status="404",uri="/**",} 1.0
http_server_requests_seconds_sum{application="springboot-prometheus",exception="None",method="GET",outcome="CLIENT_ERROR",region="iids",status="404",uri="/**",} 0.010432659
http_server_requests_seconds_count{application="springboot-prometheus",exception="None",method="GET",outcome="SUCCESS",region="iids",status="200",uri="/actuator",} 1.0
http_server_requests_seconds_sum{application="springboot-prometheus",exception="None",method="GET",outcome="SUCCESS",region="iids",status="200",uri="/actuator",} 0.071231044
http_server_requests_seconds_count{application="springboot-prometheus",exception="None",method="GET",outcome="SUCCESS",region="iids",status="200",uri="/actuator/prometheus",} 28.0
http_server_requests_seconds_sum{application="springboot-prometheus",exception="None",method="GET",outcome="SUCCESS",region="iids",status="200",uri="/actuator/prometheus",} 0.21368709
# HELP http_server_requests_seconds_max
# TYPE http_server_requests_seconds_max gauge
http_server_requests_seconds_max{application="springboot-prometheus",exception="None",method="GET",outcome="CLIENT_ERROR",region="iids",status="404",uri="/**",} 0.010432659
http_server_requests_seconds_max{application="springboot-prometheus",exception="None",method="GET",outcome="SUCCESS",region="iids",status="200",uri="/actuator",} 0.071231044
http_server_requests_seconds_max{application="springboot-prometheus",exception="None",method="GET",outcome="SUCCESS",region="iids",status="200",uri="/actuator/prometheus",} 0.089629576
# HELP logback_events_total Number of error level events that made it to the logs
# TYPE logback_events_total counter
logback_events_total{application="springboot-prometheus",level="error",region="iids",} 0.0
logback_events_total{application="springboot-prometheus",level="debug",region="iids",} 0.0
logback_events_total{application="springboot-prometheus",level="info",region="iids",} 7.0
logback_events_total{application="springboot-prometheus",level="trace",region="iids",} 0.0
logback_events_total{application="springboot-prometheus",level="warn",region="iids",} 0.0
# HELP jvm_memory_committed_bytes The amount of memory in bytes that is committed for the Java virtual machine to use
# TYPE jvm_memory_committed_bytes gauge
jvm_memory_committed_bytes{application="springboot-prometheus",area="heap",id="Eden Space",region="iids",} 7.1630848E7
jvm_memory_committed_bytes{application="springboot-prometheus",area="heap",id="Tenured Gen",region="iids",} 1.78978816E8
jvm_memory_committed_bytes{application="springboot-prometheus",area="nonheap",id="Metaspace",region="iids",} 3.9714816E7
jvm_memory_committed_bytes{application="springboot-prometheus",area="nonheap",id="Compressed Class Space",region="iids",} 5111808.0
jvm_memory_committed_bytes{application="springboot-prometheus",area="heap",id="Survivor Space",region="iids",} 8912896.0
jvm_memory_committed_bytes{application="springboot-prometheus",area="nonheap",id="Code Cache",region="iids",} 1.0747904E7
# HELP jvm_buffer_count_buffers An estimate of the number of buffers in the pool
# TYPE jvm_buffer_count_buffers gauge
jvm_buffer_count_buffers{application="springboot-prometheus",id="mapped",region="iids",} 0.0
jvm_buffer_count_buffers{application="springboot-prometheus",id="direct",region="iids",} 10.0
# HELP process_start_time_seconds Start time of the process since unix epoch.
# TYPE process_start_time_seconds gauge
process_start_time_seconds{application="springboot-prometheus",region="iids",} 1.637828102856E9
# HELP process_files_open_files The open file descriptor count
# TYPE process_files_open_files gauge
process_files_open_files{application="springboot-prometheus",region="iids",} 26.0
# HELP jvm_gc_max_data_size_bytes Max size of old generation memory pool
# TYPE jvm_gc_max_data_size_bytes gauge
jvm_gc_max_data_size_bytes{application="springboot-prometheus",region="iids",} 1.78978816E8
# HELP jvm_gc_memory_allocated_bytes_total Incremented for an increase in the size of the young generation memory pool after one GC to before the next
# TYPE jvm_gc_memory_allocated_bytes_total counter
jvm_gc_memory_allocated_bytes_total{application="springboot-prometheus",region="iids",} 1.63422192E8
# HELP jvm_classes_unloaded_classes_total The total number of classes unloaded since the Java virtual machine has started execution
# TYPE jvm_classes_unloaded_classes_total counter
jvm_classes_unloaded_classes_total{application="springboot-prometheus",region="iids",} 0.0
# HELP jvm_memory_max_bytes The maximum amount of memory in bytes that can be used for memory management
# TYPE jvm_memory_max_bytes gauge
jvm_memory_max_bytes{application="springboot-prometheus",area="heap",id="Eden Space",region="iids",} 7.1630848E7
jvm_memory_max_bytes{application="springboot-prometheus",area="heap",id="Tenured Gen",region="iids",} 1.78978816E8
jvm_memory_max_bytes{application="springboot-prometheus",area="nonheap",id="Metaspace",region="iids",} -1.0
jvm_memory_max_bytes{application="springboot-prometheus",area="nonheap",id="Compressed Class Space",region="iids",} 1.073741824E9
jvm_memory_max_bytes{application="springboot-prometheus",area="heap",id="Survivor Space",region="iids",} 8912896.0
jvm_memory_max_bytes{application="springboot-prometheus",area="nonheap",id="Code Cache",region="iids",} 2.5165824E8
# HELP jvm_threads_states_threads The current number of threads having NEW state
# TYPE jvm_threads_states_threads gauge
jvm_threads_states_threads{application="springboot-prometheus",region="iids",state="blocked",} 0.0
jvm_threads_states_threads{application="springboot-prometheus",region="iids",state="terminated",} 0.0
jvm_threads_states_threads{application="springboot-prometheus",region="iids",state="waiting",} 12.0
jvm_threads_states_threads{application="springboot-prometheus",region="iids",state="timed-waiting",} 2.0
jvm_threads_states_threads{application="springboot-prometheus",region="iids",state="new",} 0.0
jvm_threads_states_threads{application="springboot-prometheus",region="iids",state="runnable",} 6.0
# HELP system_cpu_count The number of processors available to the Java virtual machine
# TYPE system_cpu_count gauge
system_cpu_count{application="springboot-prometheus",region="iids",} 1.0
# HELP jvm_buffer_total_capacity_bytes An estimate of the total capacity of the buffers in this pool
# TYPE jvm_buffer_total_capacity_bytes gauge
jvm_buffer_total_capacity_bytes{application="springboot-prometheus",id="mapped",region="iids",} 0.0
jvm_buffer_total_capacity_bytes{application="springboot-prometheus",id="direct",region="iids",} 81920.0
# HELP tomcat_sessions_created_sessions_total
# TYPE tomcat_sessions_created_sessions_total counter
tomcat_sessions_created_sessions_total{application="springboot-prometheus",region="iids",} 0.0
# HELP jvm_memory_used_bytes The amount of used memory
# TYPE jvm_memory_used_bytes gauge
jvm_memory_used_bytes{application="springboot-prometheus",area="heap",id="Eden Space",region="iids",} 4.7401328E7
jvm_memory_used_bytes{application="springboot-prometheus",area="heap",id="Tenured Gen",region="iids",} 1.4121968E7
jvm_memory_used_bytes{application="springboot-prometheus",area="nonheap",id="Metaspace",region="iids",} 3.69704E7
jvm_memory_used_bytes{application="springboot-prometheus",area="nonheap",id="Compressed Class Space",region="iids",} 4569744.0
jvm_memory_used_bytes{application="springboot-prometheus",area="heap",id="Survivor Space",region="iids",} 0.0
jvm_memory_used_bytes{application="springboot-prometheus",area="nonheap",id="Code Cache",region="iids",} 9866496.0
# HELP process_cpu_usage The "recent cpu usage" for the Java Virtual Machine process
# TYPE process_cpu_usage gauge
process_cpu_usage{application="springboot-prometheus",region="iids",} 0.0012414649286157666
# HELP jvm_threads_live_threads The current number of live threads including both daemon and non-daemon threads
# TYPE jvm_threads_live_threads gauge
jvm_threads_live_threads{application="springboot-prometheus",region="iids",} 20.0
# HELP tomcat_sessions_expired_sessions_total
# TYPE tomcat_sessions_expired_sessions_total counter
tomcat_sessions_expired_sessions_total{application="springboot-prometheus",region="iids",} 0.0
# HELP tomcat_sessions_alive_max_seconds
# TYPE tomcat_sessions_alive_max_seconds gauge
tomcat_sessions_alive_max_seconds{application="springboot-prometheus",region="iids",} 0.0
# HELP process_files_max_files The maximum file descriptor count
# TYPE process_files_max_files gauge
process_files_max_files{application="springboot-prometheus",region="iids",} 1048576.0
# HELP jvm_gc_live_data_size_bytes Size of old generation memory pool after a full GC
# TYPE jvm_gc_live_data_size_bytes gauge
jvm_gc_live_data_size_bytes{application="springboot-prometheus",region="iids",} 1.4121968E7
# HELP system_load_average_1m The sum of the number of runnable entities queued to available processors and the number of runnable entities running on the available processors averaged over a period of time
# TYPE system_load_average_1m gauge
system_load_average_1m{application="springboot-prometheus",region="iids",} 0.22705078125
# HELP tomcat_sessions_active_current_sessions
# TYPE tomcat_sessions_active_current_sessions gauge
tomcat_sessions_active_current_sessions{application="springboot-prometheus",region="iids",} 0.0
# HELP tomcat_sessions_active_max_sessions
# TYPE tomcat_sessions_active_max_sessions gauge
tomcat_sessions_active_max_sessions{application="springboot-prometheus",region="iids",} 0.0
# HELP process_uptime_seconds The uptime of the Java virtual machine
# TYPE process_uptime_seconds gauge
process_uptime_seconds{application="springboot-prometheus",region="iids",} 147.396
# HELP tomcat_sessions_rejected_sessions_total
# TYPE tomcat_sessions_rejected_sessions_total counter
tomcat_sessions_rejected_sessions_total{application="springboot-prometheus",region="iids",} 0.0
# HELP jvm_classes_loaded_classes The number of classes that are currently loaded in the Java virtual machine
# TYPE jvm_classes_loaded_classes gauge
jvm_classes_loaded_classes{application="springboot-prometheus",region="iids",} 6944.0
# HELP jvm_gc_memory_promoted_bytes_total Count of positive increases in the size of the old generation memory pool before GC to after GC
# TYPE jvm_gc_memory_promoted_bytes_total counter
jvm_gc_memory_promoted_bytes_total{application="springboot-prometheus",region="iids",} 6409976.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
### 查看指标
http://localhost:8080/actuator
http://localhost:8080/actuator/prometheus
http://localhost:8080/actuator/metrics
http://localhost:8080/actuator/metrics/jvm.memory.max
http://localhost:8080/actuator/loggers
http://localhost:8080/actuator/prometheus
3.2.创建ServiceMonitor
msa-servicemonitor.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[root@k8s-m1 ~]# cat msa-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: msa-ext-prometheus
name: msa-servicemonitor
namespace: monitoring
spec:
endpoints:
- interval: 15s
port: msa
jobLabel: msa-ext-prometheus-monitor
namespaceSelector:
matchNames:
- dev #目标服务的namespaces
selector:
matchLabels:
app: msa-ext-prometheus #目标服务的labels
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
[root@k8s-master prometheus]# kubectl apply -f msa-servicemonitor.yaml
servicemonitor.monitoring.coreos.com/msa-servicemonitor created
[root@k8s-master prometheus]# kubectl get servicemonitor -n monitoring
NAME AGE
alertmanager 28h
blackbox-exporter 28h
coredns 28h
grafana 28h
kube-apiserver 28h
kube-controller-manager 28h
kube-scheduler 28h
kube-state-metrics 28h
kubelet 28h
msa-servicemonitor 39s
node-exporter 28h
prometheus-adapter 28h
prometheus-k8s 28h
prometheus-operator 28h
# 没成功
3.3.传统配置
https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/additional-scrape-config.md
1.创建文件
prometheus-additional.yaml
1
2
3
4
5
6
7
8
9
10
11
12
- job_name: spring-boot-actuator
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator
# 参考
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
2.创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
2.
kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run -oyaml > additional-scrape-configs.yaml
[root@k8s-master prometheus]# kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run -oyaml > additional-scrape-configs.yaml
W1125 17:01:27.653622 50590 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
[root@k8s-master prometheus]# ll
total 344
-rw-r--r-- 1 root root 435 Nov 25 17:01 additional-scrape-configs.yaml
-rw-r--r-- 1 root root 225 Nov 25 17:00 prometheus-additional.yaml
[root@k8s-master prometheus]# vim additional-scrape-configs.yaml
apiVersion: v1
data:
prometheus-additional.yaml: LSBqb2JfbmFtZTogc3ByaW5nLWJvb3QtYWN0dWF0b3IKICBtZXRyaWNzX3BhdGg6ICcvYWN0dWF0b3IvcHJvbWV0aGV1cycKICBzY3JhcGVfaW50ZXJ2YWw6IDVzCiAgc3RhdGljX2NvbmZpZ3M6CiAgICAtIHRhcmdldHM6IFsnbXNhLWV4dC1wcm9tZXRoZXVzLmRldi5zdmMuY2x1c3Rlci5sb2NhbDo4MTU4J10KICAgICAgbGFiZWxzOgogICAgICAgIGluc3RhbmNlOiBzcHJpbmctYWN0dWF0b3IK
kind: Secret
metadata:
creationTimestamp: null
name: additional-scrape-configs
[root@k8s-master prometheus]# kubectl apply -f additional-scrape-configs.yaml -n monitoring
secret/additional-scrape-configs created
3.
#prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
labels:
prometheus: prometheus
spec:
replicas: 2
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
# 添加
additionalScrapeConfigs:
name: additional-scrape-configs
key: prometheus-additional.yaml
[root@k8s-master manifests]# kubectl apply -f prometheus-prometheus.yaml
prometheus.monitoring.coreos.com/k8s configured
[root@k8s-master manifests]# kubectl delete pod prometheus-k8s-0 -n monitoring
pod "prometheus-k8s-0" deleted
[root@k8s-master manifests]# kubectl delete pod prometheus-k8s-1 -n monitoring
pod "prometheus-k8s-1" deleted
3.测试
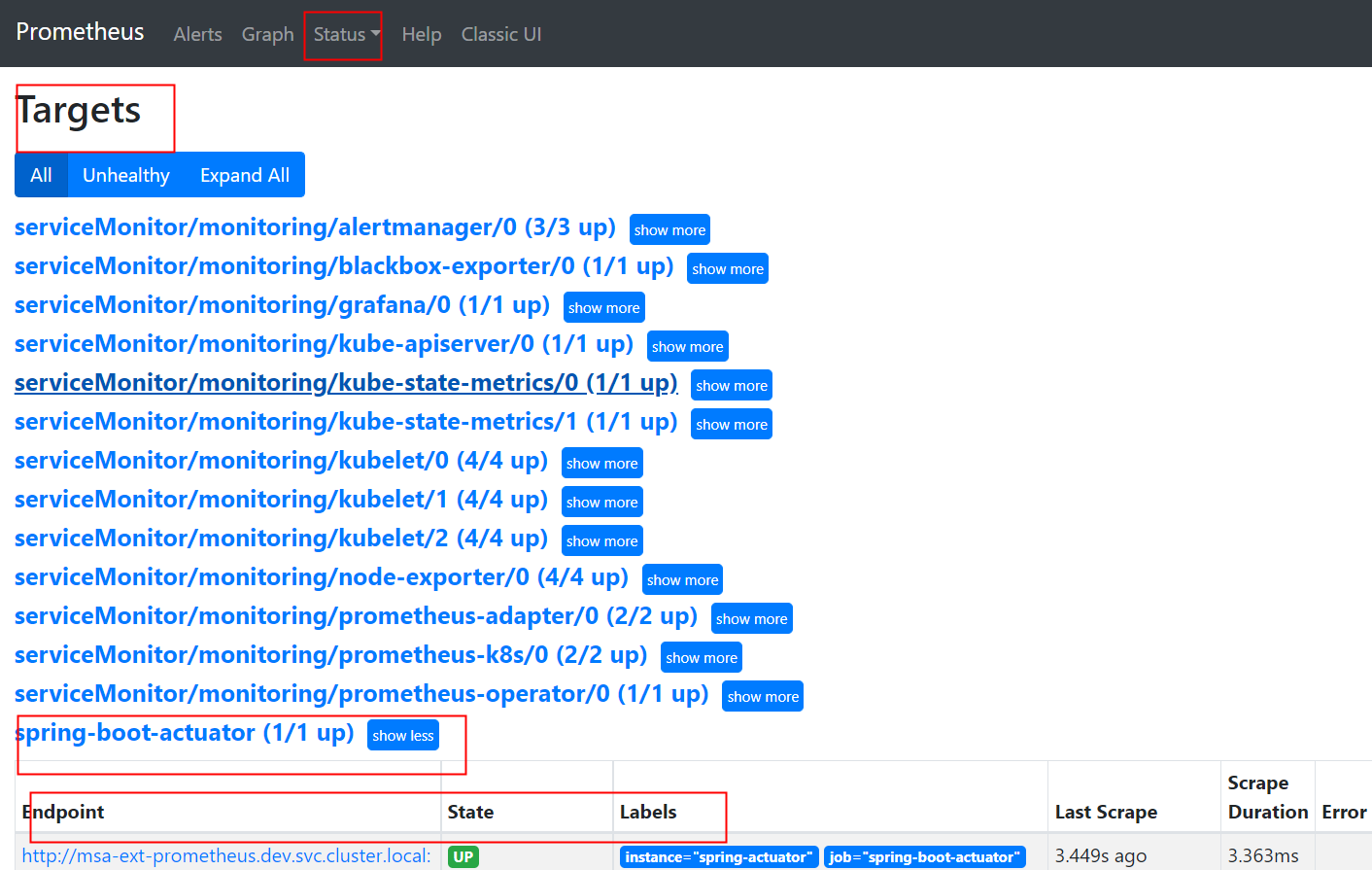
4.增加新配置
修改prometheus-additional.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- job_name: spring-boot-actuator
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator
- job_name: spring-boot
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator-1
1
2
3
4
5
6
7
[root@k8s-master prometheus]# kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run -oyaml > additional-scrape-configs.yaml
W1126 09:53:24.608990 62215 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
[root@k8s-master prometheus]# kubectl apply -f additional-scrape-configs.yaml -n monitoring
secret/additional-scrape-configs configured
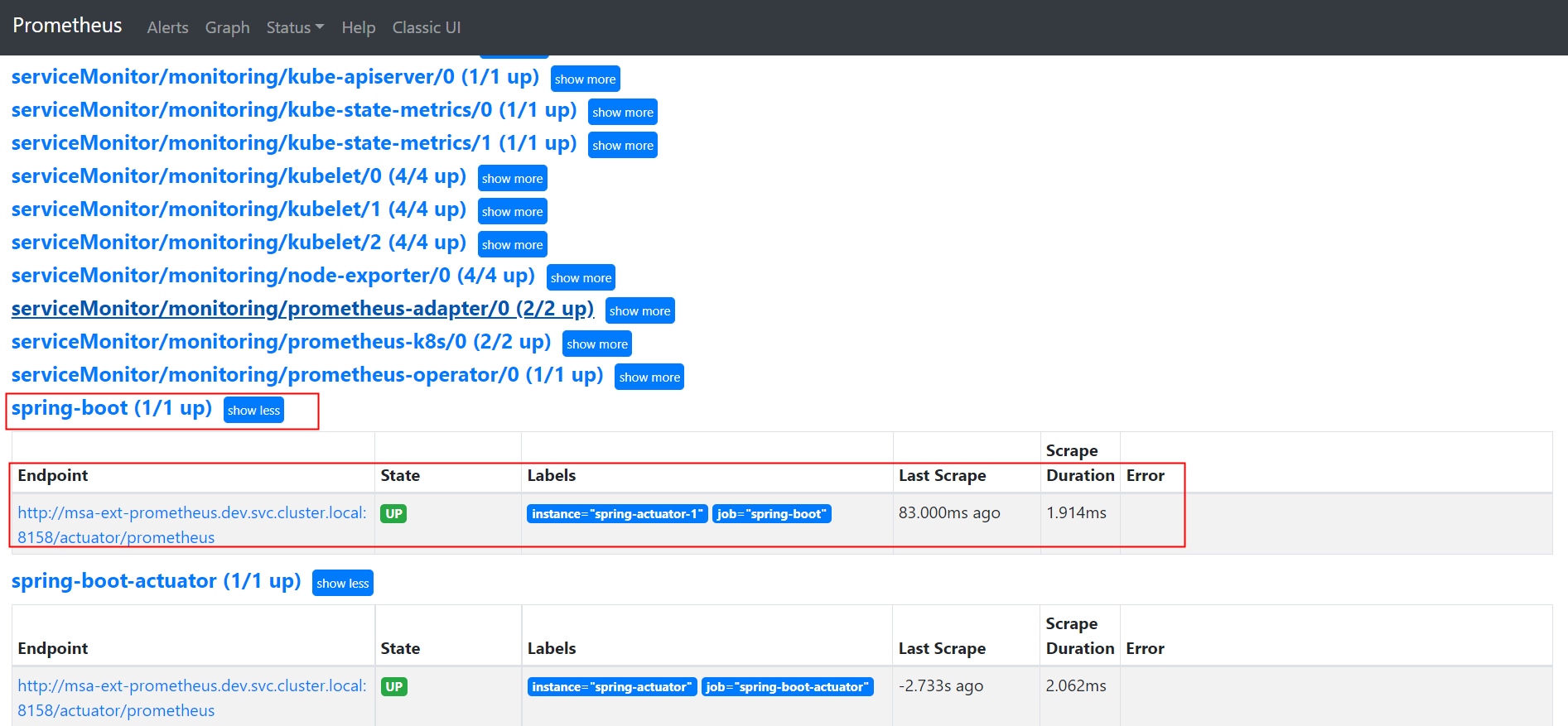
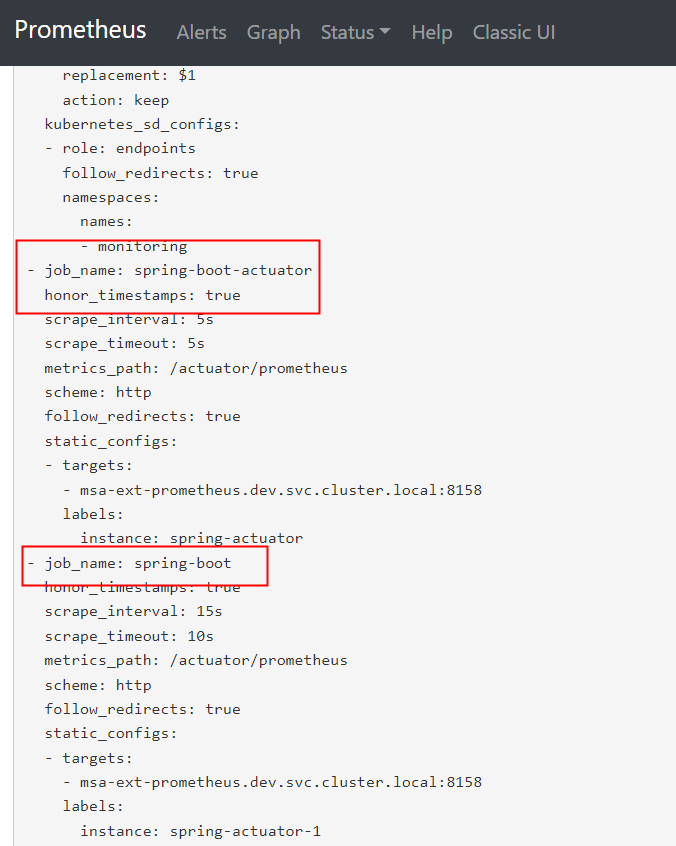
3.4.配置Grafana
1
2
3
4
5
6
7
### 选择模板
# 4701
https://grafana.com/grafana/dashboards/4701
# 11955
https://grafana.com/grafana/dashboards/11955
4.监控集群外部服务
外部服务选择MySQL,MySQL部署在K8S外部。
4.1.安装MySQL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 搭建数据库
#创建目录
mkdir -p /ntms/mysql/conf
mkdir -p /ntms/mysql/data
chmod 777 * -R /ntms/mysql/conf
chmod 777 * -R /ntms/mysql/data
#创建配置文件
vim /ntms/mysql/conf/my.cnf
#输入一下内容
[mysqld]
log-bin=mysql-bin #开启二进制日志
server-id=119 #服务id,取本机IP最后三位
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#启动容器
docker run -d --restart=always \
-p 3306:3306 \
-v /ntms/mysql/data:/var/lib/mysql \
-v /ntms/mysql/conf:/etc/mysql/ \
-e MYSQL_ROOT_PASSWORD=root \
--name mysql \
percona:5.7.23
#进入mysql容器内部
docker exec -it mysql-master bash
#登陆mysql
mysql -u root -p
4.2.mysqld_exporter
1
2
3
4
5
6
7
# github
https://github.com/prometheus/mysqld_exporter
# dockerhub
mysqld_exporter
https://registry.hub.docker.com/r/prom/mysqld-exporter
安装exporter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
docker run -d --network host --name mysqld-exporter --restart=always \
-e DATA_SOURCE_NAME="root:root@(172.51.216.98:3306)/" \
prom/mysqld-exporter
### 访问地址
http://172.51.216.98:9104/metrics
curl '172.51.216.98:9104/metrics'
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0.000229989
go_gc_duration_seconds{quantile="0.25"} 0.000229989
go_gc_duration_seconds{quantile="0.5"} 0.000229989
go_gc_duration_seconds{quantile="0.75"} 0.000229989
go_gc_duration_seconds{quantile="1"} 0.000229989
go_gc_duration_seconds_sum 0.000229989
go_gc_duration_seconds_count 1
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 7
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.16.4"} 1
# HELP go_memstats_alloc_bytes Number of bytes allocated and still in use.
# TYPE go_memstats_alloc_bytes gauge
go_memstats_alloc_bytes 1.355664e+06
# HELP go_memstats_alloc_bytes_total Total number of bytes allocated, even if freed.
# TYPE go_memstats_alloc_bytes_total counter
go_memstats_alloc_bytes_total 3.581928e+06
# HELP go_memstats_buck_hash_sys_bytes Number of bytes used by the profiling bucket hash table.
# TYPE go_memstats_buck_hash_sys_bytes gauge
go_memstats_buck_hash_sys_bytes 1.446768e+06
# HELP go_memstats_frees_total Total number of frees.
# TYPE go_memstats_frees_total counter
go_memstats_frees_total 31105
# HELP go_memstats_gc_cpu_fraction The fraction of this program's available CPU time used by the GC since the program started.
# TYPE go_memstats_gc_cpu_fraction gauge
go_memstats_gc_cpu_fraction 4.591226769073576e-06
# HELP go_memstats_gc_sys_bytes Number of bytes used for garbage collection system metadata.
# TYPE go_memstats_gc_sys_bytes gauge
go_memstats_gc_sys_bytes 4.817184e+06
# HELP go_memstats_heap_alloc_bytes Number of heap bytes allocated and still in use.
# TYPE go_memstats_heap_alloc_bytes gauge
go_memstats_heap_alloc_bytes 1.355664e+06
# HELP go_memstats_heap_idle_bytes Number of heap bytes waiting to be used.
# TYPE go_memstats_heap_idle_bytes gauge
go_memstats_heap_idle_bytes 6.3463424e+07
# HELP go_memstats_heap_inuse_bytes Number of heap bytes that are in use.
# TYPE go_memstats_heap_inuse_bytes gauge
go_memstats_heap_inuse_bytes 3.121152e+06
# HELP go_memstats_heap_objects Number of allocated objects.
# TYPE go_memstats_heap_objects gauge
go_memstats_heap_objects 13039
# HELP go_memstats_heap_released_bytes Number of heap bytes released to OS.
# TYPE go_memstats_heap_released_bytes gauge
go_memstats_heap_released_bytes 6.2251008e+07
# HELP go_memstats_heap_sys_bytes Number of heap bytes obtained from system.
# TYPE go_memstats_heap_sys_bytes gauge
go_memstats_heap_sys_bytes 6.6584576e+07
# HELP go_memstats_last_gc_time_seconds Number of seconds since 1970 of last garbage collection.
......
4.3.创建Endpoints
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# service-mysql-exporter.yaml
kind: Service
apiVersion: v1
metadata:
namespace: dev
name: service-mysql-exporter
labels:
app: service-mysql-exporter
spec:
ports:
- protocol: TCP
port: 9104
targetPort: 9104
type: ClusterIP
---
kind: Endpoints
apiVersion: v1
metadata:
namespace: dev
name: service-mysql-exporter
labels:
app: service-mysql-exporter
subsets:
- addresses:
- ip: 172.51.216.98
ports:
- protocol: TCP
port: 9104
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
[root@k8s-master prometheus]# kubectl apply -f service-mysql-exporter.yaml
service/service-mysql-exporter created
endpoints/service-mysql-exporter created
[root@k8s-master prometheus]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-mysql-exporter ClusterIP 10.101.125.113 <none> 9104/TCP 100s
[root@k8s-master prometheus]# kubectl get ep -n dev
NAME ENDPOINTS AGE
service-mysql-exporter 172.51.216.98:9104 33s
[root@k8s-master prometheus]# curl 10.101.125.113:9104/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0.000229989
go_gc_duration_seconds{quantile="0.25"} 0.000229989
go_gc_duration_seconds{quantile="0.5"} 0.000229989
go_gc_duration_seconds{quantile="0.75"} 0.000229989
go_gc_duration_seconds{quantile="1"} 0.000229989
go_gc_duration_seconds_sum 0.000229989
go_gc_duration_seconds_count 1
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 7
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
......
# K8S 中的容器使用访问
svcname.namespace.svc.cluster.local:port
service-mysql-exporter.dev.svc.cluster.local:9104
4.4.创建ServiceMonitor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# mysql-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: mysql-servicemonitor
namespace: monitoring
labels:
app: service-mysql-exporter
spec:
selector:
matchLabels:
app: service-mysql-exporter
namespaceSelector:
matchNames:
- dev
endpoints:
- port: metrics
interval: 10s
honorLabels: true
1
2
3
4
5
6
7
[root@k8s-master prometheus]# kubectl apply -f mysql-servicemonitor.yaml
servicemonitor.monitoring.coreos.com/mysql-servicemonitor created
[root@k8s-master prometheus]# kubectl get servicemonitor -n monitoring
NAME AGE
mysql-servicemonitor 30s
未成功
4.5.传统配置
https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/additional-scrape-config.md
1.修改文件
prometheus-additional.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
- job_name: spring-boot
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator
- job_name: mysql
scrape_interval: 10s
static_configs:
- targets: ['service-mysql-exporter.dev.svc.cluster.local:9104']
labels:
instance: mysqld
2.创建
1
2
3
4
5
6
7
[root@k8s-master prometheus]# kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run -oyaml > additional-scrape-configs.yaml
W1126 11:57:08.632627 78468 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
[root@k8s-master prometheus]# kubectl apply -f additional-scrape-configs.yaml -n monitoring
secret/additional-scrape-configs configured
4.6.配置Grafana
1
2
3
4
5
6
7
### 选择模板
# 11323
https://grafana.com/grafana/dashboards/11323
# 7362
https://grafana.com/grafana/dashboards/7362
5.微服务配置
5.1.服务发现机制
但是如果使用微服务的话,一个服务一个服务的配置似乎太麻烦,Prometheus提供了很多服务发现的机制去统一配置服务,具体可以查看官网介绍:https://prometheus.io/docs/prometheus/latest/configuration/configuration/
提供了Consul的服务发现机制,没有Eureka的服务发现机制。但是如果Eureka想要使用的话可以通过配置一个适配器的方式,使用consul_sd_config配置的方式使用Prometheus服务发现。
创建一个Eureka Server,在配置中加入eureka-consul-adapter依赖,pom文件完整内容如下所示。
1
2
3
4
5
<dependency>
<groupId>at.twinformatics</groupId>
<artifactId>eureka-consul-adapter</artifactId>
<version>1.1.0</version>
</dependency>
Eureka Consul Adapter
Maven
1
2
3
4
5
<dependency>
<groupId>at.twinformatics</groupId>
<artifactId>eureka-consul-adapter</artifactId>
<version>${eureka-consul-adapter.version}<version>
</dependency>
Requirements
- Java 1.8+
Versions 1.1.x and later
- Spring Boot 2.1.x
- Spring Cloud Greenwich
Versions 1.0.x and later
- Spring Boot 2.0.x
- Spring Cloud Finchley
Versions 0.x
- Spring Boot 1.5.x
- Spring Cloud Edgware
5.2.创建微服务
1.修改Eureka服务配置
pom.xml
1
2
3
4
5
<dependency>
<groupId>at.twinformatics</groupId>
<artifactId>eureka-consul-adapter</artifactId>
<version>1.1.0</version>
</dependency>
2.创建镜像
创建镜像,上传到镜像仓库。
3.服务配置
注册中心(eureka-server)、生产者(msa-deploy-producer)、消费者(msa-deploy-consumer)
msa-eureka.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
apiVersion: v1
kind: Service
metadata:
namespace: dev
name: msa-eureka
labels:
app: msa-eureka
spec:
type: NodePort
ports:
- port: 10001
name: msa-eureka
targetPort: 10001
nodePort: 30001 #对外暴露30001端口
selector:
app: msa-eureka
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: dev
name: msa-eureka
spec:
serviceName: msa-eureka
replicas: 3
selector:
matchLabels:
app: msa-eureka
template:
metadata:
labels:
app: msa-eureka
spec:
imagePullSecrets:
- name: harborsecret #对应创建私有镜像密钥Secret
containers:
- name: msa-eureka
image: 172.51.216.85:8888/springcloud/msa-eureka:2.1.0
ports:
- containerPort: 10001
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: EUREKA_SERVER
value: "http://msa-eureka-0.msa-eureka.dev:10001/eureka/,http://msa-eureka-1.msa-eureka.dev:10001/eureka/,http://msa-eureka-2.msa-eureka.dev:10001/eureka/"
- name: EUREKA_INSTANCE_HOSTNAME
value: ${MY_POD_NAME}.msa-eureka.dev
- name: ACTIVE
value: "-Dspring.profiles.active=k8s"
podManagementPolicy: "Parallel"
msa-deploy-producer.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
apiVersion: v1
kind: Service
metadata:
namespace: dev
name: msa-deploy-producer
labels:
app: msa-deploy-producer
spec:
type: ClusterIP
ports:
- port: 8911
targetPort: 8911
selector:
app: msa-deploy-producer
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: dev
name: msa-deploy-producer
spec:
replicas: 3
selector:
matchLabels:
app: msa-deploy-producer
template:
metadata:
labels:
app: msa-deploy-producer
spec:
imagePullSecrets:
- name: harborsecret #对应创建私有镜像密钥Secret
containers:
- name: msa-deploy-producer
image: 172.51.216.85:8888/springcloud/msa-deploy-producer:2.0.0
imagePullPolicy: Always #如果省略imagePullPolicy,策略为IfNotPresent
ports:
- containerPort: 8911
env:
- name: EUREKA_SERVER
value: "http://msa-eureka-0.msa-eureka.dev:10001/eureka/,http://msa-eureka-1.msa-eureka.dev:10001/eureka/,http://msa-eureka-2.msa-eureka.dev:10001/eureka/"
- name: ACTIVE
value: "-Dspring.profiles.active=k8s"
- name: DASHBOARD
value: "sentinel-server.dev.svc.cluster.local:8858"
msa-deploy-consumer.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
apiVersion: v1
kind: Service
metadata:
namespace: dev
name: msa-deploy-consumer
labels:
app: msa-deploy-consumer
spec:
type: ClusterIP
ports:
- port: 8912
targetPort: 8912
selector:
app: msa-deploy-consumer
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: dev
name: msa-deploy-consumer
spec:
replicas: 3
selector:
matchLabels:
app: msa-deploy-consumer
template:
metadata:
labels:
app: msa-deploy-consumer
spec:
imagePullSecrets:
- name: harborsecret #对应创建私有镜像密钥Secret
containers:
- name: msa-deploy-consumer
image: 172.51.216.85:8888/springcloud/msa-deploy-consumer:2.0.0
imagePullPolicy: Always #如果省略imagePullPolicy,策略为IfNotPresent
ports:
- containerPort: 8912
env:
- name: EUREKA_SERVER
value: "http://msa-eureka-0.msa-eureka.dev:10001/eureka/,http://msa-eureka-1.msa-eureka.dev:10001/eureka/,http://msa-eureka-2.msa-eureka.dev:10001/eureka/"
- name: ACTIVE
value: "-Dspring.profiles.active=k8s"
- name: DASHBOARD
value: "sentinel-server.dev.svc.cluster.local:8858"
4.创建服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[root@k8s-master prometheus]# kubectl get all -n dev
NAME READY STATUS RESTARTS AGE
pod/msa-deploy-consumer-6b75cf55d-tgd82 1/1 Running 0 33s
pod/msa-deploy-consumer-6b75cf55d-x25lm 1/1 Running 0 33s
pod/msa-deploy-consumer-6b75cf55d-z22pv 1/1 Running 0 33s
pod/msa-deploy-producer-7965c98bbf-6cxf2 1/1 Running 0 80s
pod/msa-deploy-producer-7965c98bbf-vfp2v 1/1 Running 0 80s
pod/msa-deploy-producer-7965c98bbf-xzst2 1/1 Running 0 80s
pod/msa-eureka-0 1/1 Running 0 2m12s
pod/msa-eureka-1 1/1 Running 0 2m12s
pod/msa-eureka-2 1/1 Running 0 2m12s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/msa-deploy-consumer ClusterIP 10.102.251.125 <none> 8912/TCP 33s
service/msa-deploy-producer ClusterIP 10.110.134.51 <none> 8911/TCP 80s
service/msa-eureka NodePort 10.102.205.141 <none> 10001:30001/TCP 2m13s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/msa-deploy-consumer 3/3 3 3 33s
deployment.apps/msa-deploy-producer 3/3 3 3 80s
NAME DESIRED CURRENT READY AGE
replicaset.apps/msa-deploy-consumer-6b75cf55d 3 3 3 33s
replicaset.apps/msa-deploy-producer-7965c98bbf 3 3 3 80s
NAME READY AGE
statefulset.apps/msa-eureka 3/3 2m13s
5.3.Prometheus配置
1.修改文件
prometheus-additional.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- job_name: spring-boot
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator
- job_name: mysql
scrape_interval: 10s
static_configs:
- targets: ['service-mysql-exporter.dev.svc.cluster.local:9104']
labels:
instance: mysqld
- job_name: consul-prometheus
scheme: http
metrics_path: '/actuator/prometheus'
consul_sd_configs:
- server: 'msa-eureka-0.msa-eureka.dev:10001'
scheme: http
services: [msa-deploy-producer]
未测试通过
分别配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
- job_name: spring-boot
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-ext-prometheus.dev.svc.cluster.local:8158']
labels:
instance: spring-actuator
- job_name: mysql
scrape_interval: 10s
static_configs:
- targets: ['service-mysql-exporter.dev.svc.cluster.local:9104']
labels:
instance: mysqld
- job_name: consul-prometheus
scheme: http
metrics_path: '/actuator/prometheus'
consul_sd_configs:
- server: 'msa-eureka-0.msa-eureka.dev:10001'
scheme: http
services: [msa-deploy-producer]
- job_name: msa-eureka
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-eureka-0.msa-eureka.dev:10001']
labels:
instance: msa-eureka-0
- targets: ['msa-eureka-1.msa-eureka.dev:10001']
labels:
instance: msa-eureka-1
- targets: ['msa-eureka-2.msa-eureka.dev:10001']
labels:
instance: msa-eureka-2
- job_name: msa-deploy-producer
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-deploy-producer.dev.svc.cluster.local:8911']
labels:
instance: spring-actuator
- job_name: msa-deploy-consumer
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ['msa-deploy-consumer.dev.svc.cluster.local:8912']
labels:
instance: spring-actuator
2.创建
1
2
3
4
5
6
7
[root@k8s-master prometheus]# kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run -oyaml > additional-scrape-configs.yaml
W1126 11:57:08.632627 78468 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
[root@k8s-master prometheus]# kubectl apply -f additional-scrape-configs.yaml -n monitoring
secret/additional-scrape-configs configured
4.6.配置Grafana
1
2
3
4
5
6
7
### 选择模板
# 4701
https://grafana.com/grafana/dashboards/4701
# 11955
https://grafana.com/grafana/dashboards/11955
